
Open-source AI модели: Пълно ръководство и сравнение [2026]
Open-source AI модели контролират 50% от LLM пазара през 2026. DeepSeek R1, Llama 4 Maverick, Qwen: сравнение, цени и break-even калкулация за self-hosting.
Накратко: Open-source AI моделите контролират над 50% от LLM пазара през 2026 г., а разликата в производителността спрямо затворените системи е намаляла до почти нула. Ако работите с AI — независимо дали като разработчик, IT мениджър или технологичен ръководител — разбирането на тази смяна е вече стратегически приоритет, не опция.
Ключови факти:
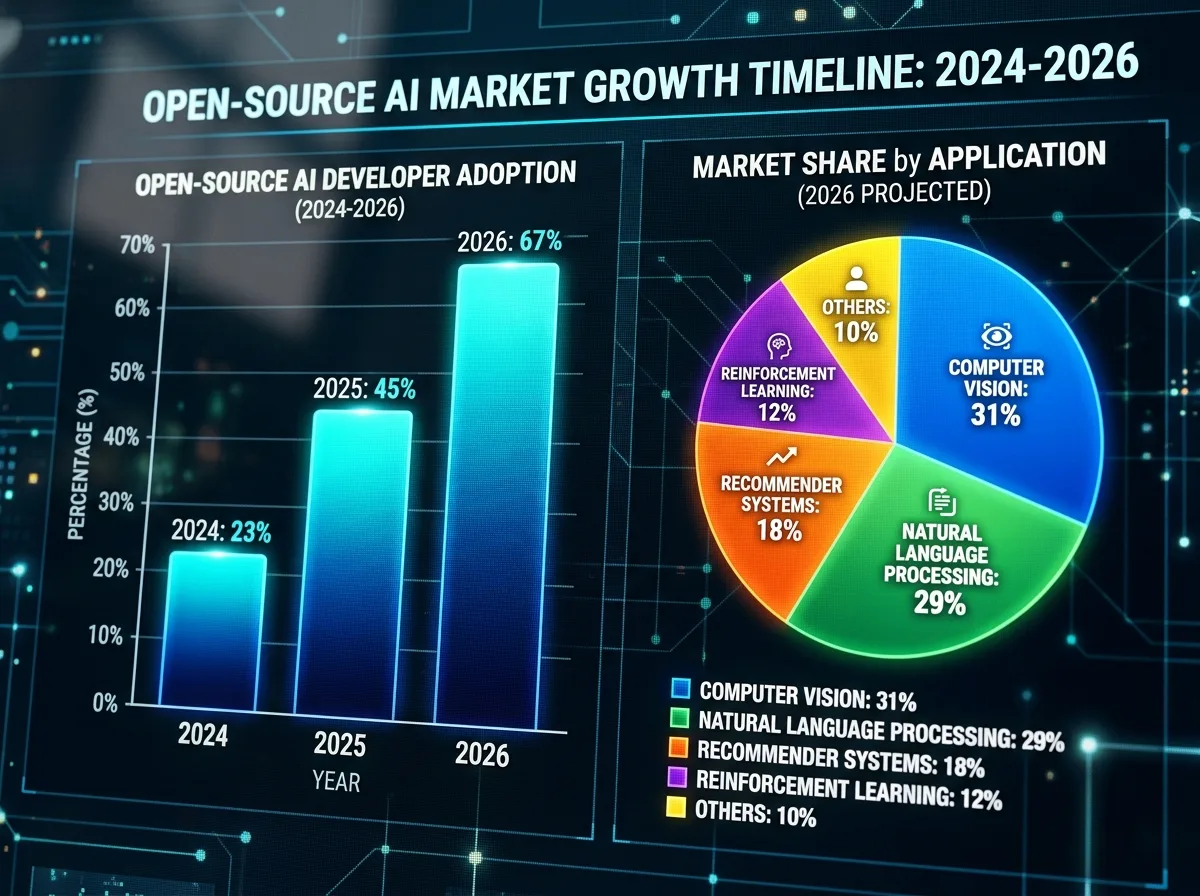
- 50%+ от LLM пазара е под контрола на open-source модели през 2026 г.
- 15% глобален пазарен дял за китайски open-source модели (DeepSeek, Qwen) — от едва 1% година по-рано
- 340% ръст на пазара на open-source AI година спрямо година
- $6M — разходът за обучение на DeepSeek R1, срещу $100M+ за GPT-4 (16,7 пъти разлика)
- 67% от разработчиците пускат open-source модели в производство (от 23% година по-рано)
- 700M+ изтегляния на Qwen в Hugging Face до януари 2026 г.
- 0,3 процентни пункта — разликата в MMLU benchmark между open-source и proprietary модели (беше 17,5 преди година)
Open-source AI моделите през 2026: Текущото състояние на пазара
Когато DeepSeek обучи модел с 671 милиарда параметра за $6 милиона — 16 пъти по-евтино от GPT-4 — инвеститорите в AI инфраструктура загубиха над $1 трилион пазарна капитализация за един ден. Този момент промени не само пазара, но и фундаменталните предположения за бариерите за навлизане в AI. Според данни от developers.redhat.com, пет модела от клас пионер с отворен лиценз доказаха, че качественото reasoning не изисква затворени системи, а локалните решения вече контролират повече от половината LLM пазар.
Най-значимата промяна е в производителността. Преди година разликата между open-source и proprietary модели в MMLU benchmark беше 17,5 процентни пункта — достатъчна, за да оправдае значително по-високите разходи за затворените системи. Към началото на 2026 г. тази разлика е свита до 0,3 процентни пункта, според swfte.com. Практически погледнато, за повечето бизнес приложения разликата е незначима.
Китайските модели са двигателят на тази промяна. DeepSeek и Qwen са нараснали от 1% обобщен глобален пазарен дял на AI през януари 2025 г. до приблизително 15% до януари 2026 г. — най-бързият цикъл на приемане в историята на AI. Qwen от Alibaba Cloud надвишава 700 милиона изтегляния в Hugging Face, което го прави най-широко използваната open-source AI система в света.
Пазарът расте с темп, който малко анализатори са предвидили. Разширяването на разработчиците, използващи open-source модели в производство, е нараснало от 23% на 67% само за една година, според programming-helper.com. Общият пазар на open-source AI е нараснал с 340% година спрямо година — цифра, която поставя тази тенденция сред най-бързо развиващите се в технологичния сектор.
Какви са ключовите тенденции при open-source AI моделите през 2026?
Тенденция 1: Паритет в производителността с proprietary системи
Какво се случва: Разликата в производителността между open-source и затворени AI модели практически изчезна за стандартните бизнес задачи.
Данни: Както споменахме, MMLU разликата е свита до 0,3 процентни пункта. На ниво конкретни модели, DeepSeek R1 постига 79,8% Pass@1 на AIME и 97,4% на MATH — резултати, надвишаващи OpenAI o1 на тези задачи. Llama 3.1 405B беше първият open-source модел, съперничещ на топ proprietary системи в общо познание, математика и многоезичен превод, според Meta AI. С издаването на Llama 4 Maverick (април 2025), Meta затвърди тенденцията — Maverick с 400B параметра (17B активни) и 128 експерта надмина GPT-4o и Gemini 2.0 Flash в ключови benchmark-ове.
Какво означава: Организациите вече не трябва да правят компромис с производителността, за да избегнат vendor lock-in и да намалят разходите. Изборът между open-source и затворени системи е преминал от технически въпрос към стратегически и финансов.
Кога ще се усети: Тенденцията е вече факт за математически и кодиращи задачи. За по-сложни multi-modal и reasoning задачи паритетът се очаква да се задълбочи до края на 2026 г.
Тенденция 2: Китайските модели преначертават конкурентната карта
Какво се случва: DeepSeek и Qwen са преминали от регионални играчи до глобални лидери в open-source AI пространството.
Данни: Qwen от Alibaba Cloud надвишава 700 милиона изтегляния в Hugging Face и държи над 30% от всички изтегляния на модели на платформата, надминавайки Llama, според trendforce.com. DeepSeek самостоятелно държи 4% от глобалния пазар на chatbot. Контрастът е показателен: САЩ са инвестирали $527 милиарда в AI инфраструктура, а китайски екип е постигнал конкурентен резултат при разход, по-нисък от заплатите на един малък ML екип в Силициевата долина.
Какво означава: Ефективността на обучение — не само изчислителната мощ — е новото конкурентно предимство. Това преначертава предположенията за това кой може да участва в AI надпреварата.
Кога ще се усети: Тенденцията вече е факт. Въпросът е дали западните компании ще адаптират своите подходи към ефективност на обучение.
Тенденция 3: Локалното внедряване става стандарт
Какво се случва: Организациите преминават от cloud-базирани API към локални и on-premises решения за AI.
Данни: Двата от всеки трима разработчици вече пускат open-source модели в производство — троен ръст спрямо година по-рано, според programming-helper.com. Основните двигатели са суверенността на данните, GDPR съотговорствието и EU AI Act изискванията. DeepSeek R1 работи напълно офлайн на Mac хардуер — факт, който демократизира достъпа до мощни reasoning модели.
Какво означава: Инфраструктурата за AI се децентрализира. Облачните доставчици ще трябва да предложат по-конкурентни цени и по-голяма гъвкавост, за да задържат корпоративните клиенти.
Кога ще се усети: Тенденцията е в ход. EU AI Act изискванията ще ускорят прехода към локални решения за регулирани индустрии в Европа.
Тенденция 4: Fine-tuning като критична организационна компетенция
Какво се случва: Организациите все по-активно адаптират open-source модели към специфичните си данни и задачи, вместо да разчитат на универсални cloud модели.
Данни: Според IBM, организациите могат да фино-настройват open-source AI модели на собствените си бизнес данни и да ги оптимизират за конкретни задачи. Откритият характер на тези системи позволява прозрачност за това как моделът е построен, обучен и как взема решения. Qwen 3.5 9B модел надвишава модели 13 пъти по-големи при специализирани задачи, след fine-tuning.
Какво означава: Конкурентното предимство вече не е в достъпа до модела, а в качеството на данните и компетентността за fine-tuning. Организациите, които изградят тази способност рано, ще имат трайно предимство.
Кога ще се усети: Fine-tuning вече е достъпен за средни организации. До края на 2026 г. се очаква да стане стандартна практика в технологично зрелите компании.
Тенденция 5: Регулаторната среда благоприятства open-source
Какво се случва: EU AI Act и GDPR изискванията създават регулаторен натиск, който по-лесно се управлява с open-source решения.
Данни: Прозрачността и способността за одит са ключови изисквания на EU AI Act. Open-source моделите позволяват на организациите да запазят пълен контрол над AI stack-а — включително кога, как и дали да надградят, персонализират или одитират системата, според cmr.berkeley.edu. Локалното внедряване елиминира въпросите за трансгранично предаване на данни.
Какво означава: За европейски организации — включително български — open-source моделите предлагат по-ясен път към регулаторно съотговорствие. Повече за регулаторните изисквания можете да прочетете в нашия анализ EU AI Act: Какво означава новата регулация за България.
Кога ще се усети: EU AI Act изискванията влизат в сила поетапно. Организациите, работещи с AI в регулирани сектори, трябва да адресират въпроса за одитируемост вече.
Какво казват данните: Сравнение на ключовите open-source AI модели
| Модел | Параметри | AIME % | Лиценз | API цена/M |
|---|---|---|---|---|
| DeepSeek R1 | 671B | 79.8% | MIT | $0.02 |
| Llama 4 Maverick | 400B (17B акт.) | Над GPT-4o | Llama* | $0.27 |
| Llama 3.1 | 8B-405B | ~GPT-4 | Llama* | $0.10-0.49 |
| Mistral Large 3 | 675B активни | Топ клас | Apache 2.0 | $2.00 |
| Qwen 3.5 | 0.8B-9B | Над 13x по-гол. | Apache 2.0 | $0 |
| GPT-4 (сравнение) | Затворен | Референция | Proprietary | $15+ |
*Llama лицензът прилага приемлива политика на употреба, която ограничава определени приложения — Meta's използване на термина "open-source" е оспорено от общността.
Данните показват ясна тенденция: open-source моделите предлагат сравнима или по-добра производителност при значително по-ниски разходи за API достъп. DeepSeek R1 с MIT лиценз е особено привлекателен за търговски приложения — пълна свобода за употреба без текущи абонаментни разходи при локално внедряване.
Разминаването в цените е значимо. Together AI предлага open-source модели на $0.18 за милион входни токена, докато OpenAI таксува $15+ за милион токена — разлика от над 80 пъти. Според MIT Sloan, затворените модели струват на потребителите средно шест пъти повече от отворените, а оптималното преразпределение на търсенето би генерирало $25 милиарда годишна икономия глобално.
Как open-source AI моделите променят различните индустрии?
Технологии и разработка: Разработчиците са основните бенефициенти на тенденцията. Инструменти като Ollama позволяват стартиране на Llama, Qwen или Mistral локално за секунди — без cloud зависимост, без таксуване на токени. За кодиращи задачи, DeepSeek R1 предлага видим процес на reasoning, което го прави особено полезен за debugging и архитектурни решения. Вижте как open-source моделите се сравняват с комерсиалните решения за код в нашия анализ AI за писане на код 2026: Copilot vs Cursor vs Claude.
Финанси и банкиране: Финансовите институции работят с чувствителни данни, при които изпращането на информация към external API е регулаторно проблематично. Локалното внедряване на open-source модели позволява AI-базиран анализ на документи, fraud detection и клиентско обслужване при пълна суверенност на данните. GDPR и финансовите регулации правят on-premises решенията предпочитан избор.
Здравеопазване: Медицинските данни са сред най-строго регулираните. Open-source модели, внедрени локално, позволяват анализ на медицинска документация, подпомагане на диагностиката и административна автоматизация без риск от нарушаване на пациентска поверителност. Прозрачността на модела — достъп до тежести и архитектура — е ключова за одитируемост в здравния сектор.
Образование и изследвания: Академичните институции имат достъп до мощни AI инструменти без абонаментни разходи. Qwen 3.5 с Apache 2.0 лиценз и Llama 3.3 са широко използвани в изследователски среди. Fine-tuning на специализирани академични данни позволява създаване на домейн-специфични асистенти за конкретни научни области.
- ✓Пълна контрола върху данните и инфраструктурата - организацията решава кога и как да надгради
- ✓90% по-ниски разходи спрямо затворени API - затворените модели струват средно 6 пъти повече
- ✓Без vendor lock-in - смяната на модел не изисква промяна на договори или миграция на данни
- ✓Fine-tuning на специфични данни - персонализиране за конкретен домейн и задачи
- ✓Прозрачност и одитируемост - достъп до тежести и архитектура за регулаторно съотговорствие
- ✓MIT и Apache 2.0 лицензи предоставят пълна свобода за търговска употреба
- ×По-голяма организационна отговорност за сигурност, съотговорствие и управление на жизнения цикъл
- ×Значителни изчислителни ресурси за локално внедряване на най-големите модели (675B параметри)
- ×Общностна поддръжка може да е непълна или несъвместима с организационните стандарти за сигурност
- ×Липса на plug-and-play функционалност - изисква допълнителна техническа работа преди готовност за производство
- ×Обучението на данни не е публично разкрито дори при open-source модели - ограничена прозрачност на training data
- ×Llama лицензът ограничава определени употреби - не е истински open-source според OSI дефиницията
Как да стартирате с open-source AI модели: Практическо ръководство
Open-source AI моделите са достъпни за стартиране в рамките на минути с правилните инструменти. Следващите стъпки покриват пътя от нулата до работеща локална AI система.
Стъпка 1: Изтеглете Ollama
Ollama е приложение, което позволява пускане на LLM модели локално с прост интерфейс на командния ред. Инсталацията е стандартна за macOS, Linux и Windows — без конфигурация на cloud акаунти или API ключове.
Стъпка 2: Изберете модел
Hugging Face е домакин на близо 500 000 open-source AI модела. За начало препоръчваме Llama 3.3 70B за общи задачи, DeepSeek R1 за reasoning и математика, или Qwen 3.5 9B за многоезично съдържание и ресурсно ограничена среда. Навигирайте към страницата на модела, кликнете "Use this model" и копирайте командата.
Стъпка 3: Пуснете локално — 30 секунди
ollama run llama4 # Llama 4 Maverick (най-новият)
# или
ollama run llama3.1:70b # Llama 3.1 70B (по-лек вариант)
# или
ollama run qwen:3-72b
# или
ollama run deepseek-r1:671b
Никакъв cloud. Никакво таксуване. Тридесет секунди до работеща AI система на вашия хардуер.
Стъпка 4: Fine-tuning (опционално)
Разработчиците могат напълно да персонализират моделите за конкретни нужди — обучение на нови набори от данни и допълнително fine-tuning. Това позволява по-пълна реализация на генеративния AI потенциал за специфични домейни. За оптимизация на промптовете вижте нашето Prompt инженерство: Пълно ръководство.
Стъпка 5: RAG интеграция
За по-сложни приложения интегрирайте модела с RAG pipeline:
- LlamaIndex или LangChain — оркестрация на retrieval и generation
- Docling — парсване на документи (PDF, Word, HTML)
- Pinecone или Weaviate — vector database за съхранение на embeddings
- Together AI или Hugging Face Hub — ако предпочитате cloud inference вместо локално
Пример за RAG система с Qwen 3.5 + LangChain + Pinecone: заредете документи чрез Docling, генерирайте embeddings с Qwen, съхранете ги в Pinecone, и използвайте LangChain за оркестрация на заявките. За автоматизация на workflow-и без код вижте n8n: AI автоматизация без код.
DeepSeek R1: Анализ на open-source AI модела, обучен за $6 милиона
DeepSeek R1 е може би най-дискутираният open-source AI модел от 2025 г. насам — и с основание, подкрепено от конкретни данни.
Разходи за обучение: DeepSeek R1 е обучен за $6 милиона, докато GPT-4 е струвал $100+ милиона — 16,7 пъти разлика в разходите, според byteiota.com. Това не е просто финансова статистика — то преначертава предположенията за бариерите за навлизане в AI разработката.
Производителност: DeepSeek R1 постига 79,8% Pass@1 на AIME и 97,4% на MATH, надвишавайки OpenAI o1 на тези задачи, според capmad.com. Моделът разполага с 671 милиарда параметра и предлага видим процес на reasoning — потребителите могат да проследят стъпките на мислене, което е особено ценно за верификация на резултатите.
Лиценз и употреба: MIT лицензът на DeepSeek R1 предоставя пълна свобода за търговска употреба без текущи абонаментни разходи. Моделът работи напълно офлайн на Mac хардуер, което го прави достъпен за индивидуални разработчици и малки екипи.
Пазарен ефект: DeepSeek самостоятелно държи 4% от глобалния пазар на chatbot само година след пускането си, според byteiota.com.
"DeepSeek R1 е един от най-удивителните и впечатляващи пробиви, които някога съм виждал — и като open-source, дарен на света." — Marc Andreessen, съосновател на Andreessen Horowitz
Техническото обяснение за ефективността на обучение включва иновативни подходи към reinforcement learning и архитектурни оптимизации, които намаляват изчислителните изисквания без значима загуба на производителност. Това е методологичен принос, не просто евтин хардуер.
Безопасност и рискове при open-source AI модели: Балансирана оценка
Open-source AI моделите предлагат реални предимства в сигурността, но и специфични рискове, които организациите трябва да управляват проактивно.
Предимства за сигурност: Прозрачността е може би най-значимото предимство. С достъп до изходния код и тежести на модела, развойните екипи могат да разберат точно как AI системата взема решения, според anaconda.com. Това е критично за одитируемост и регулаторно съотговорствие — особено при EU AI Act изискванията за обяснимост. Вижте повече за етичните измерения в нашия анализ Етика на AI: Какво трябва да знаем.
Организационна отговорност: Open-source LLM-ите предполагат по-голяма отговорност на организацията за операции, съотговорствие и управление на жизнения цикъл, според odsc.medium.com. Няма централизирана поддръжка — организацията е отговорна за patch management, мониторинг на уязвимости и актуализации.
Лицензни рискове: Разликата между лицензите е практически важна:
| Лиценз | Свобода | Ограничения |
|---|---|---|
| MIT (DeepSeek R1) | Пълна търговска свобода | Практически никакви |
| Apache 2.0 (Qwen, Mistral) | Широка търговска употреба | Запазване на атрибуция |
| Llama лиценз | Ограничена | Забранява определени употреби, не е OSI-одобрен |
Данни за обучение: Важно ограничение е, че малко open-source AI компании или проекти разкриват публично данните, използвани за обучение, според anaconda.com. "Open-source" се отнася до тежестите и кода — не задължително до пълната прозрачност на training pipeline-а.
Изчислителни изисквания: Използването на open-source модели може да изисква значителни изчислителни ресурси, които натоварват инфраструктурата на по-малките организации, според MIT Sloan. Моделите с 671B параметра изискват специализиран хардуер — по-малките варианти (7B-70B) са по-достъпни.
Как България се вписва в световния контекст на open-source AI?
Българският IT сектор е реална база за приемане на open-source AI. Според BASSCOM Barometer 2025, софтуерният сектор вече надвишава 60 000 служители в над 6 100 компании, с приходи от BGN 11 милиарда и ръст от 11,5% през 2024 г. Тези 60 000 разработчици са потенциални потребители на open-source AI модели за ежедневната си работа.
На инфраструктурно ниво, България прави значителна стъпка. INSAIT и Sofia Tech Park са одобрени за проект на стойност €90 милиона за изграждане на AI фабрика BRAIN++ — една от шестте нови европейски AI фабрики, финансирани от EuroHPC JU. Суперкомпютърът Discoverer++ ще позволи обучение и inference на големи AI модели директно в България, което премахва нуждата от скъп cloud достъп за по-мощни модели.
България като член на ЕС е под юрисдикцията на EU AI Act и GDPR — двата регулаторни рамки, които благоприятстват локалното внедряване. Организациите в регулирани сектори (финанси, здравеопазване, публична администрация) имат стимул да изберат on-premises open-source решения. Предизвикателството обаче остава в дигиталните умения — България е сред последните в ЕС по DESI индекс, с резултат под 35 точки при EU средно от 43.
Конкретен български принос към open-source AI екосистемата вече съществува. INSAIT съвместно с ETH Zurich и българската компания LatticeFlow създадоха COMPL-AI — първата EU рамка, която превежда регулаторните изисквания на EU AI Act в конкретни технически тестове. Чрез нея тестваха DeepSeek R1, Llama, GPT и модели на Anthropic, Google и Mistral. Резултатът: дестилираните DeepSeek модели се справят добре с токсично съдържание, но се класират последни по киберсигурност и показват повишени рискове от "prompt hijacking". Този инструмент е публичен и безплатен — всяка организация в България може да провери дали избраният open-source модел отговаря на EU AI Act преди внедряване.
Образованието също реагира: Софийски университет предлага магистърска програма "Изкуствен интелект" с курсове по Machine Learning, Deep Learning, NLP и Computer Vision, а ТУ-София — "Интелигентни системи и изкуствен интелект". Общо 7 български университета предлагат магистратури, фокусирани върху AI.
Езиковата поддръжка е практически въпрос. Qwen 3, при 235 милиарда параметра, е обучен на 30+ езика — включително по-малко разпространени европейски езици. За малки и средни компании от тези 6 100 фирми, open-source моделите предлагат достъп до AI без абонаментни разходи в USD. Инструменти като Ollama работят на стандартен потребителски хардуер — дори Llama 3.1 8B може да работи на лаптоп с 16GB RAM.
Какво е бъдещето на open-source AI моделите: Прогнози за 2026–2027
Open-source AI моделите ще продължат да набират пазарен дял, движени от три конвергиращи фактора: регулаторен натиск, ценово предимство и достигнат паритет в производителността.
Китайските модели ще продължат да растат. От 1% до 15% глобален пазарен дял за една година е темп, който — ако се запази дори частично — поставя DeepSeek и Qwen сред доминиращите играчи до края на 2027 г. Методологичните иновации в ефективността на обучение, демонстрирани от DeepSeek R1, ще бъдат адаптирани и от западни играчи.
Локалното внедряване ще стане стандарт за регулирани индустрии. EU AI Act изискванията за одитируемост и обяснимост са по-лесно изпълними с open-source модели, внедрени on-premises. Организациите, които изчакват, ще се изправят пред по-сложна миграция по-късно.
Хибридните подходи — комбинация от локални open-source модели за чувствителни данни и cloud API за по-малко критични задачи — ще станат преобладаващата архитектура. Това е вече видима тенденция при 41% от анкетираните в a16z Enterprise Survey, които планират да разширят употребата на open-source модели, и допълнителни 41%, готови да превключат ако производителността е еквивалентна.
Fine-tuning ще се превърне в критична организационна компетенция. Достъпът до модела ще бъде безплатен — конкурентното предимство ще идва от качеството на данните и способността за адаптация. Това е особено релевантно за как open-source моделите захранват следващото поколение AI агенти: Автономната работна сила на 2026.
Open-source AI модели: Break-even калкулация — кога self-hosting се изплаща?
Едно от ключовите решения при преминаване към open-source AI е дали да използвате cloud API или да инвестирате в собствена инфраструктура. Следващата таблица показва break-even анализ за различни обеми на употреба:
| Месечен обем | Cloud API* | Self-host** | Спестявания |
|---|---|---|---|
| 100K tokens | $1.50 | $150 (сървър) | API е 100x по-евтин |
| 1M tokens | $15 | $150 | API е 10x по-евтин |
| 10M tokens | $150 | $150 | Break-even точка |
| 100M tokens | $1,500 | $150-300 | Self-host 5-10x по-евтин |
| 1B tokens | $15,000 | $300-500 | Self-host 30-50x по-евтин |
*Cloud API: базирано на средна цена от $15/M tokens за GPT-4 клас модел. **Self-host: базирано на наем на GPU сървър (RTX 4090, ~$150/месец) за Llama 3.1 8B или Qwen 3.5 9B. По-големите модели (70B+) изискват по-мощен хардуер ($500-1500/месец).
Извод: При под 10 милиона токена месечно, cloud API е по-изгоден заради нулевите оперативни разходи. Над 10 милиона токена — self-hosting спестява значителни суми. За организации с над 100 милиона токена месечно (типично за enterprise chatbot или document processing), self-hosting на open-source модел спестява $1,200-1,350 месечно, или $14,400-16,200 годишно. При екип от 50+ разработчици, които активно използват AI за код — обемите лесно надвишават 1 милиард токена месечно, което прави self-hosting икономически задължителен.
Какво означават open-source AI моделите за вас — конкретни действия
За разработчици:
- Инсталирайте Ollama и тествайте DeepSeek R1 или Llama 4 Maverick (или Llama 3.1 8B за по-слаб хардуер) локално — 30 минути инвестиция за разбиране на практическите разлики спрямо cloud API
- Изградете прост RAG pipeline с LangChain + Pinecone + локален модел — това е умението, което ще бъде най-търсено в следващите 12 месеца
- Проучете fine-tuning с LoRA за специфичен домейн — дори малък dataset може да подобри значително производителността за конкретни задачи
За бизнеси:
- Направете одит на текущите AI разходи — ако плащате за cloud LLM API, изчислете дали open-source алтернатива при Together AI ($0.18/M токена) или локално внедряване е икономически оправдано
- Оценете регулаторните изисквания — ако работите с лични данни или сте в регулиран сектор, консултирайте се за EU AI Act съотговорствие при текущата AI архитектура
- Пилотирайте с нискорискова употреба — вътрешни инструменти, документация, код review — преди мигриране на критични системи
За студенти и кариерно развитие:
- Изградете портфолио с open-source AI проекти — работодателите търсят практически опит с Ollama, LangChain и fine-tuning, не само теоретично познание
- Следете Hugging Face и Papers With Code — тук се появяват новите модели и изследвания преди да достигнат mainstream медиите
- Научете основите на prompt engineering за open-source модели — поведението се различава от cloud API и оптимизацията изисква специфични умения
Често задавани въпроси
Какво точно е open-source AI модел и как се различава от GPT-4?+
Наистина ли open-source моделите са толкова добри, колкото GPT-4?+
Колко струва локалното внедряване на open-source модел?+
Безопасно ли е да използвам open-source AI модели за чувствителни бизнес данни?+
Кой open-source модел да избера за начало?+
Как EU AI Act засяга употребата на open-source AI модели в България?+
Заключение: Ключовите изводи
Open-source AI моделите са преминали от алтернатива за ентусиасти до доминираща пазарна сила. Повече от половината LLM пазар, мнозинството от разработчиците в производство и практически нулева разлика в производителността спрямо proprietary системи — това не е тенденция, която предстои да се случи. Тя вече се случва.
Най-важният извод е икономически: затворените модели струват средно шест пъти повече от отворените, а оптималното преразпределение би генерирало $25 милиарда годишна икономия глобално. За организации, които плащат значителни суми за cloud LLM API, анализът на алтернативите е вече финансово задължение.
В следващите 12 месеца очаквайте: по-нататъшен ръст на китайските модели (от 15% към по-висок глобален дял), ускорено приемане на локално внедряване в регулирани европейски индустрии и fine-tuning като стандартна практика в технологично зрелите организации. Хибридните архитектури — локален open-source за чувствителни данни, cloud за по-малко критични задачи — ще станат преобладаващи.
Три конкретни действия, които да предприемете сега: (1) Тествайте Ollama с DeepSeek R1 или Llama 4 Maverick локално — инвестицията е 30 минути; (2) Направете одит на текущите AI разходи и сравнете с open-source алтернативи; (3) Оценете регулаторните изисквания за вашия сектор в контекста на EU AI Act и GDPR.
Допълнителни ресурси
- State of Open Source AI Models 2025 — Red Hat — задълбочен технически преглед на водещите модели
- Open Models Have Benefits — MIT Sloan Management Review — академичен анализ на икономиката на open-source AI
- The Coming Disruption — Berkeley Haas CMR — стратегически анализ на конкурентната динамика
- Hugging Face Model Hub — централното хранилище за open-source AI модели
- Ollama — инструмент за локално стартиране на LLM модели
- DeepSeek R1 GitHub — официална документация и тежести
- Papers With Code — актуални benchmark резултати и изследвания
Основател на CyberNinjas.ai и Кибер Хора. Пише за AI инструменти, новини и практически ръководства.
Още статии
 AI Тенденции18 мин.
AI Тенденции18 мин.Vibe Coding: тъмната страна на AI програмирането [2026]
Vibe coding генерира 46% от кода в GitHub, но 45% съдържа уязвимости. Реални инциденти, security рискове и open source кризата — задълбочен анализ за 2026.
![Етика на AI: Какво трябва да знаем [2026]](/images/posts/etika-na-ai-kakvo-triabva-da-znaem-2026/hero.webp?dpl=dpl_CfPL7gK4jaxAoDcCJBBAQJQWWfyo) AI Тенденции21 мин.
AI Тенденции21 мин.Етика на AI: какво трябва да знаем за отговорния AI [2026]
Етика на AI: принципи, EU AI Act регулации, рискове от пристрастия и как да защитите данните си. Пълно ръководство за отговорен AI през 2026. Сравнения, цени.
 AI Тенденции11 мин.
AI Тенденции11 мин.AI срещу работните места: Професиите на бъдещето [2026]
AI работни места: кои професии изчезват и кои нови роли се раждат? Данни от WEF, Goldman Sachs и McKinsey за трансформацията на AI работните места през 2026 г.