
Google Gemma 4: най-мощният open source AI модел [2026]
Google Gemma 4 — най-мощният open source AI модел с Apache 2.0 лиценз, 89% AIME, мултимодалност и агентни workflows. Пълни бенчмаркове и сравнение [2026]
На 2 април 2026 г. Google DeepMind пусна Gemma 4 — четири open source AI модела, които преобръщат представите за това какво е възможно без облачна инфраструктура. С резултати от 89.2% на AIME 2026 (математика) и 80% на LiveCodeBench (код), 31B моделът се конкурира директно с proprietary гиганти като GPT-5.4 и Claude Opus. А най-важната промяна? За пръв път в историята на Gemma семейството, лицензът е Apache 2.0 — пълна свобода за комерсиална употреба без никакви ограничения.
Накратко: Gemma 4 предлага четири модела (от 2B до 31B параметри), Apache 2.0 лиценз без ограничения, мултимодален вход (текст, изображения, видео, аудио), native function calling за AI агенти и бенчмаркове, конкурентни с proprietary модели — 89.2% AIME, 80% LiveCodeBench, 84.3% GPQA. Работи от телефон до сървър.
Какво е Google Gemma 4 и защо привлече вниманието на AI общността
Google Gemma 4 е фамилия от четири open source AI модела, създадени от Google DeepMind върху изследванията и технологията зад Gemini 3. За разлика от Gemini, който е proprietary облачен модел достъпен само чрез API, Gemma 4 може да бъде изтеглен, модифициран и стартиран локално — на сървър, работна станция, лаптоп или дори телефон.
Четирите варианта покриват целия спектър от хардуер:
- E2B (Effective 2B) — оптимизиран за максимална скорост на мобилни устройства
- E4B (Effective 4B) — баланс между reasoning и ефективност за лаптопи
- 26B A4B (MoE) — Mixture of Experts архитектура за работни станции
- 31B Dense — максимално качество за сървъри с мощни GPU
Публикацията предизвика вълна от дискусии в Hacker News и Reddit. Според Clement Delangue, CEO на Hugging Face, смяната на лиценза е „огромна крачка напред" за цялата open source AI екосистема.
Архитектура и технически спецификации на Gemma 4 моделите
Новото поколение въвежда няколко архитектурни иновации, които обясняват драматичното подобрение спрямо предходната версия.
Hybrid Attention Design
Слоевете редуват local sliding-window attention (512–1024 токена) и global full-context attention. Това балансира ефективността при кратки контексти с разбирането на дълги документи.
Per-Layer Embeddings (PLE)
Префиксът „E" в E2B и E4B означава „effective parameters". Тези модели използват техниката Per-Layer Embeddings — вторичен embedding сигнал, който се подава към всеки decoder слой, увеличавайки ефективния капацитет на модела без добавяне на реални параметри.
Dual RoPE позиционно кодиране
Стандартни rotary position embeddings за sliding-window слоевете и пропорционални RoPE за глобалните слоеве. Това позволява 256K контекстен прозорец на по-големите модели без деградация на качеството при дълги разстояния.
Споделен KV Cache
Последните N слоя преизползват key/value тензори от по-ранни слоеве — намалявайки и паметта, и изчисленията по време на inference.
| Характеристика | E2B | E4B | 26B A4B (MoE) | 31B Dense |
|---|---|---|---|---|
| Общо параметри | 5.1B | 8B | 25.2B | 30.7B |
| Активни параметри | 2.3B | 4.5B | 3.8B | 30.7B |
| Контекстен прозорец | 128K | 128K | 256K | 256K |
| Модалности | Текст, изображения, аудио, видео | Текст, изображения, аудио, видео | Текст, изображения, видео | Текст, изображения, видео |
| Аудио вход | Да (до 30 сек) | Да (до 30 сек) | Не | Не |
| Видео вход | Да | Да | До 60 сек (1 fps) | До 60 сек (1 fps) |
| Оптимизиран за | Мобилни устройства | Лаптопи, edge | Работни станции | Сървъри, GPU клъстери |
MoE: 26B параметри, 3.8B активни
26B A4B моделът използва Mixture of Experts архитектура — от общо 25.2 милиарда параметри, при всеки токен се активират само 3.8 милиарда. Резултатът е качество, близко до 31B Dense модела, при значително по-ниски изисквания за хардуер. Тежестите на 31B модела в bfloat16 формат (без квантизация) се побират на един 80GB NVIDIA H100 GPU, а квантизираните версии работят на потребителски графични карти.
Бенчмаркове на Gemma 4: как се представят моделите
Най-впечатляващият аспект на Gemma 4 е скокът в производителността спрямо Gemma 3. Подобрението на AIME (математика) от 20.8% при Gemma 3 до 89.2% при Gemma 4 31B е едно от най-драматичните подобрения между поколения в историята на open source AI моделите.
| Бенчмарк | Gemma 4 31B | Gemma 4 26B | Gemma 4 E4B | Gemma 4 E2B |
|---|---|---|---|---|
| AIME 2026 (математика) | 89.2% | 88.3% | 42.5% | 37.5% |
| LiveCodeBench v6 (код) | 80.0% | 77.1% | 52.0% | 44.0% |
| MMLU Pro (знания) | 85.2% | 82.6% | 69.4% | 60.0% |
| GPQA Diamond (наука) | 84.3% | 82.3% | 58.6% | 43.4% |
| MMMU Pro (мултимодал) | 76.9% | 73.8% | 52.6% | 44.2% |
| t2-bench Retail (агентни) | 86.4% | 85.5% | 57.5% | 29.4% |
| Arena AI (текст) | 1452 | 1441 | N/A | N/A |
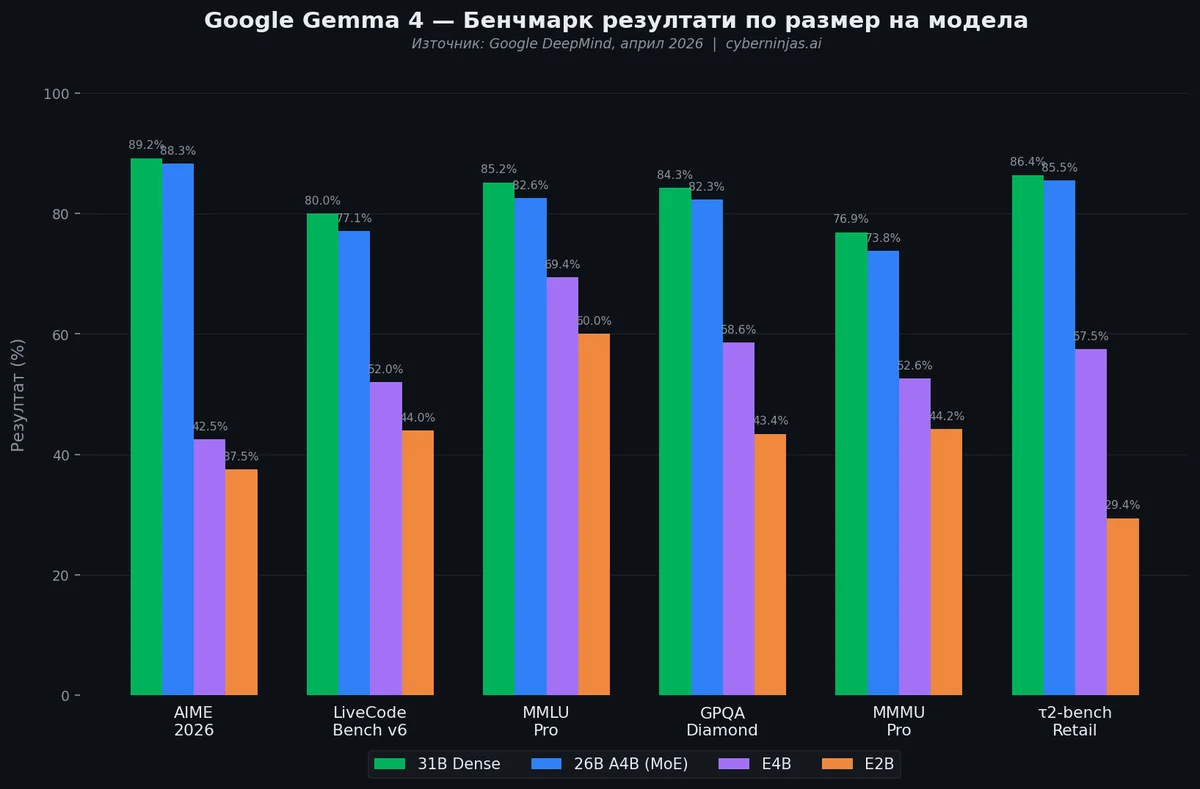
Какво означават тези числа на практика
- AIME 2026 (89.2%) — моделът решава математически задачи на ниво олимпиада с висока точност
- LiveCodeBench v6 (80%) — генерира и дебъгва код със сравнима ефективност с proprietary модели
- GPQA Diamond (84.3%) — отговаря на експертни научни въпроси (физика, химия, биология) на ниво PhD
- τ2-bench Retail (86.4%) — изпълнява агентни задачи (навигация, планиране, използване на инструменти) с висока надеждност. Предишният Gemma 3 27B постигаше едва 6.6% на същия тест
Codeforces ELO рейтингът на 31B модела достига 2150 — конкурентен с много по-големи модели.
Мултимодалните възможности на Gemma 4 в детайли
За разлика от много open source модели, които поддържат само текст, Gemma 4 предлага пълна мултимодалност още „от кутията".
Визуален вход
Всички четири модела обработват изображения и видео нативно. Vision encoder-ът използва 2D позиционно кодиране с мултидименсионален RoPE, който запазва оригиналните пропорции на изображенията. Бюджетите за токени на изображение са настройваеми — от 70 до 1120 токена, в зависимост от нужната детайлност. Моделите се справят отлично с OCR, разбиране на графики и chart analysis.
Аудио вход
E2B и E4B моделите включват USM-style conformer аудио encoder (същата архитектура като Gemma-3n). Поддържат разпознаване на реч и speech-to-translated-text на множество езици, с вход до 30 секунди аудио.
Видео разбиране
26B и 31B моделите поддържат видео до 60 секунди при 1 кадър в секунда — достатъчно за анализ на кратки клипове, инструкции и демонстрации.
Apache 2.0 лиценз: защо промяната е по-важна от бенчмарковете
Според анализ на VentureBeat, смяната на лиценза е по-значима от самите технически подобрения. Предишните Gemma версии използваха custom лиценз на Google, който включваше:
- Строга политика за забранена употреба, която Google можеше да променя едностранно
- Изискване разработчиците да прилагат правилата на Google върху всички Gemma-базирани проекти
- Custom „Harmful Use" клаузи, изискващи правна интерпретация преди enterprise адаптация
Apache 2.0 премахва всичко това. Конкретно:
- ✅ Пълна комерсиална употреба без разрешение
- ✅ Модификация и преразпространение без ограничения
- ✅ Няма лимит за месечни активни потребители (за разлика от Llama 4 с лимит 700M MAU)
- ✅ Няма acceptable use policy за налагане
- ✅ Същият лиценз като TensorFlow и Kubernetes — добре разбран от всеки правен екип
Тази промяна „може да има по-голямо значение от бенчмарковете" за реалната адаптация на модела в enterprise среда.
Агентни workflows и function calling с Gemma 4
Един от най-значимите аспекти на Gemma 4 е вграденият native function calling. Моделите поддържат структуриран JSON изход, нативни системни инструкции и извикване на функции без допълнителна настройка — директно от инсталацията.
Какво означава това на практика
Вместо да разчитате на облачни API-та за агентни приложения, с Gemma 4 можете да изградите:
- Локални AI агенти — автономни системи, които планират, изпълняват и валидират задачи без интернет
- Офлайн кодови асистенти — генериране, дебъгване и рефакториране на код директно на вашата машина
- Мултистъпкови workflows — верижно свързване на инструменти чрез native function calling
Според официалния блог на Google Developers, агентните подобрения са най-голямата разлика между Gemma 3 и Gemma 4 — моделите вече могат автономно да планират, изпълняват и коригират мултистъпкови задачи. За повече информация как AI агентите трансформират програмирането, вижте нашето ръководство за vibe coding с AI агенти.
Как да стартирате Gemma 4 на локален компютър
Моделите са достъпни чрез множество платформи и инструменти. Ето най-бързите начини:
Чрез Ollama (най-лесно)
# Инсталирайте Ollama от ollama.com
ollama run gemma4:26b # MoE модел за работни станции
ollama run gemma4:e4b # За лаптопи
ollama run gemma4:e2b # За по-слаб хардуер
Чрез Hugging Face Transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-4-31B",
device_map="auto",
torch_dtype="auto"
)
tokenizer = AutoTokenizer.from_pretrained("google/gemma-4-31B")
Хардуерни изисквания
- E2B — работи на смартфони и Raspberry Pi; минимум 4GB RAM; до 3 пъти по-бърз от E4B
- E4B — лаптоп с 8GB RAM; по-висок reasoning от E2B
- 26B A4B (MoE) — препоръчват се 16GB VRAM (RTX 4090 или еквивалент); квантизираният вариант работи на 8GB VRAM
- 31B Dense — 80GB VRAM (NVIDIA H100) за bfloat16; квантизираните версии работят на потребителски GPU
Fine-tuning с LoRA
Благодарение на LoRA (Low-Rank Adaptation), fine-tuning е достъпен дори с ограничен хардуер:
# Чрез Unsloth — поддържа E2B, E4B, 26B и 31B
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="google/gemma-4-E4B",
max_seq_length=8192,
load_in_4bit=True, # QLoRA за по-малко RAM
)
Според тестове, fine-tuning на E4B чрез QLoRA на RTX 3060 завършва за приблизително 3 часа. E2B моделът може да бъде fine-tune-нат дори на безплатен Google Colab T4 GPU.
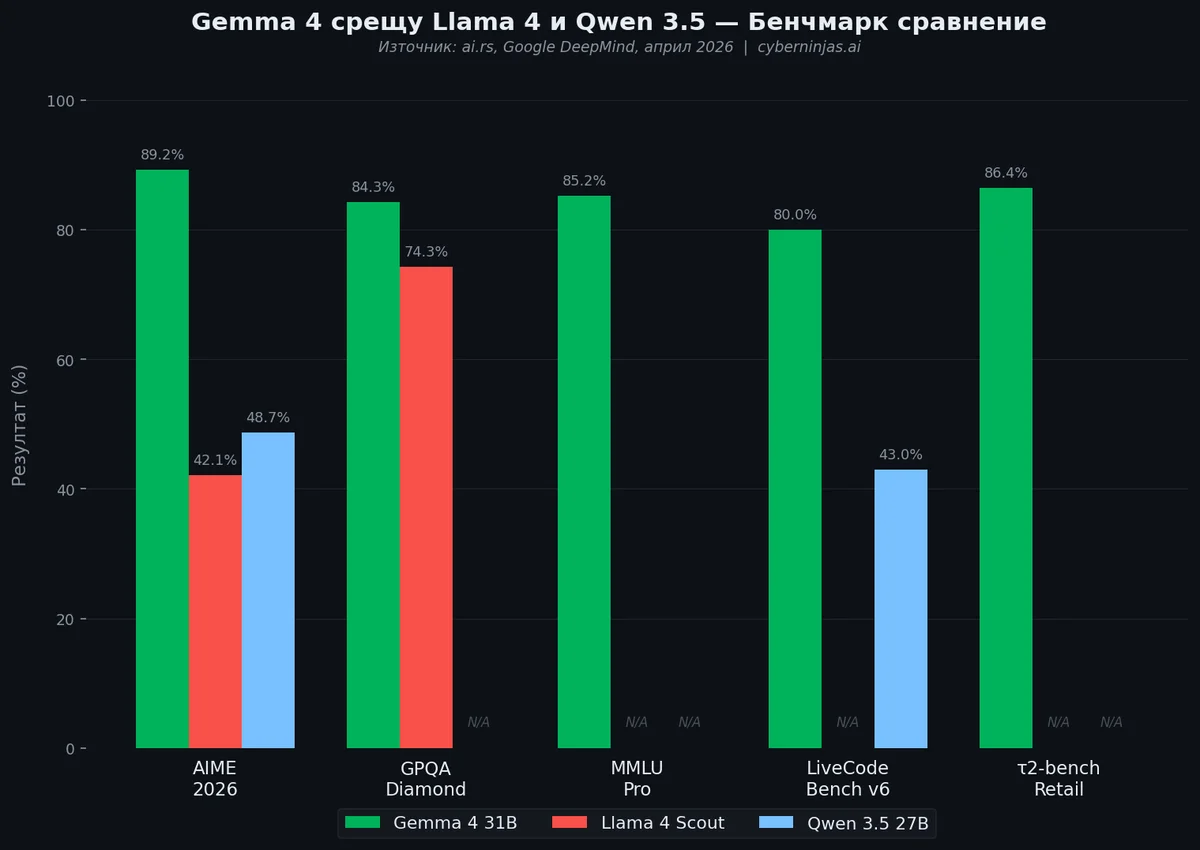
Gemma 4 срещу Llama 4 и Qwen 3.5: подробно сравнение
Трите водещи open source модела към април 2026 — от Google, Meta и Alibaba — имат различни силни страни. Ето детайлно сравнение, базирано на последните налични данни:
| Характеристика | Gemma 4 31B | Llama 4 Scout | Qwen 3.5 27B |
|---|---|---|---|
| Общо параметри | 30.7B | 109B (17B активни) | 27B |
| Контекстен прозорец | 256K | 10M | 128K |
| AIME 2026 (математика) | 89.2% | 42.1% | 48.7% |
| LiveCodeBench v6 (код) | 80.0% | N/A | ~43% |
| GPQA Diamond (наука) | 84.3% | 74.3% | N/A |
| Мултимодалност | Текст, изображения, видео | Текст, изображения | Текст, изображения |
| Аудио вход | Да (E2B/E4B) | Не | Не |
| Лиценз | Apache 2.0 | Meta Community (700M MAU) | Apache 2.0 |
| Function calling | Native | Да | Да |
| Брой езици | 140+ | N/A | Водещ в мултиезикови задачи |
Кога да изберете Gemma 4
- Нуждаете се от най-добро quality-per-parameter съотношение
- Работите с мултимодален вход (изображения, видео, аудио)
- Искате Apache 2.0 лиценз без правни усложнения
- Изграждате агентни системи с native function calling
- Искате модел, който работи на различен хардуер — от телефон до сървър
Кога да изберете Llama 4 Scout
- Нуждаете се от изключително дълъг контекст (10M токена — няма конкуренция)
- Обработвате цели codebase-ове или много дълги документи
- Имате мощен хардуер (109B параметри изискват значителни ресурси)
Кога да изберете Qwen 3.5
- Приоритетът е coding — Qwen води в SWE-bench и практическите кодови задачи
- Работите с мултиезикови приложения — Qwen има най-силна мултиезикова поддръжка
- Нуждаете се от най-широк спектър от размери от едно семейство
Ако ви интересува как Gemini 3.1 Pro (proprietary братът на Gemma 4) се представя в облака, вижте нашия преглед на Gemini 3.1 Pro. А за директно сравнение между ChatGPT, Claude и Gemini, проверете актуалния ни анализ.
Gemma 4 и България: BgGPT на INSAIT
Gemma има специално значение за българската AI екосистема. Институтът INSAIT (София) създаде BgGPT — първият публичен езиков модел за български, изграден именно върху Gemma архитектурата.
BgGPT 3.0 (базиран на Gemma 3) е наличен в размери 4B, 12B и 27B, като 27B и 9B вариантите надминават значително по-големи модели като Qwen 2.5 72B и Llama 3.1 70B при задачи на български език. Google дори цитира BgGPT като успешен пример в официалната Gemma документация.
С пускането на Gemma 4 и Apache 2.0 лиценза, INSAIT и други български организации получават още по-свободен достъп за изграждане на следващото поколение BgGPT — без правни ограничения и с драматично подобрени базови модели. Пилотни програми с BgGPT вече текат в държавни агенции като Националната агенция за приходите (НАП).
Това прави Gemma 4 не просто поредния open source модел, а стратегически важен инструмент за суверенен AI на български.
Предимства и недостатъци на Google Gemma 4
- ✓Apache 2.0 лиценз без никакви ограничения за комерсиална употреба
- ✓Четири размера за всякакъв хардуер — от телефони до сървъри
- ✓Впечатляващи бенчмаркове: 89.2% AIME, 80% LiveCodeBench, 84.3% GPQA
- ✓Пълна мултимодалност: текст, изображения, видео и аудио (E2B/E4B)
- ✓Native function calling и агентни workflows без допълнителна настройка
- ✓Ефективна MoE архитектура — 26B модел с активни само 3.8B параметри
- ✓Поддръжка на над 140 езика, включително български
- ✓LoRA/QLoRA fine-tuning дори на потребителски GPU като RTX 3060
- ×31B Dense моделът изисква 80GB VRAM за пълна точност (bfloat16)
- ×По-малките E2B/E4B модели значително отстъпват на 31B по reasoning
- ×Няма 10M контекстен прозорец като при Llama 4 Scout
- ×Аудио вход е наличен само за E2B и E4B моделите, не за 26B/31B
- ×Видео разбиране е ограничено до 60 секунди при 1 fps
- ×Отстъпва на Qwen 3.5 в някои coding бенчмаркове като SWE-bench
Често задавани въпроси за Google Gemma 4
Какво е Google Gemma 4 и каква е разликата с Gemini?+
Може ли Gemma 4 да работи на моя компютър?+
Какъв лиценз има Gemma 4?+
Поддържа ли Gemma 4 български език?+
Как Gemma 4 се сравнява с GPT-5 и Claude?+
Мога ли да fine-tune-на Gemma 4 с моите данни?+
Какво е MoE архитектура при 26B модела?+
Къде мога да изтегля Gemma 4?+
Заключение: Gemma 4 е нов стандарт за open source AI
Четвъртото поколение на Gemma не е просто поредна версия — това е фундаментална промяна в open source AI ландшафта. Комбинацията от Apache 2.0 лиценз, впечатляващи бенчмаркове, пълна мултимодалност и native агентни възможности го прави един от най-значимите open source AI releases до момента.
За разработчици, 26B MoE моделът предлага оптимално съотношение качество/ресурси — близо до 31B Dense при активни само 3.8B параметри. За бизнеси, Apache 2.0 лицензът премахва правните бариери, които спираха корпоративната адаптация на предишните Gemma версии. За изследователи, достъпът до модел с 89.2% на AIME и native function calling отваря нови възможности за автономни AI системи.
Въпреки силната конкуренция от Llama 4 (с неговия безпрецедентен 10M контекст) и Qwen 3.5 (с водещите позиции в coding), Gemma 4 се утвърждава като модел с най-висока „intelligence-per-parameter" ефективност — и това го прави задължителен за всеки, който работи с AI на устройство.
Източници:
- Google Blog — Gemma 4: Byte for byte, the most capable open models
- Google DeepMind — Gemma 4 Model Page
- Google Developers Blog — Agentic skills with Gemma 4
- VentureBeat — Gemma 4 Apache 2.0 License Analysis
- Android Developers Blog — Gemma 4 in AICore Developer Preview
- NVIDIA Technical Blog — Gemma 4 on Edge
- Gemma 4 vs Qwen 3.5 vs Llama 4 — Benchmark Comparison
- Google AI for Developers — Gemma 4 Model Card
- Hugging Face Blog — Welcome Gemma 4
- Google Open Source Blog — Gemma 4 Apache 2.0
Основател на CyberNinjas.ai и Кибер Хора. Пише за AI инструменти, новини и практически ръководства.
Още статии

BgGPT 3.0: българският AI с глас, снимки и търсене [2026]
BgGPT 3.0 е безплатният български AI от INSAIT с глас, снимки, документи и интернет търсене. Вижте какво може, как да го ползвате и струва ли си през 2026

GLM 5.2: open weights, 1M контекст и benchmarks [2026]
GLM 5.2 от Z.ai излезе с open weights под MIT лиценз и 1M контекст. Водещ open-weights резултат, benchmarks срещу Claude Opus 4.8 и GPT-5.5, цени и БГ контекст

AI браузъри: Comet, Atlas и Dia — кой да изберете [2026]
AI браузъри 2026: сравняваме Comet, ChatGPT Atlas и Dia — функции, цени, платформи, сигурност и рискове, за да изберете кой AI браузър е подходящ за вас