
RAG (Retrieval-Augmented Generation): Пълно ръководство
Научи какво е RAG и защо е критично за AI. Пълен гайд с примери, инструменти и 6-стъпков процес за имплементация. С RAG GPT-4 достига 0% халюцинации.
Накратко: В това ръководство ще научите какво е RAG, как работи в три фази и как да го внедрите в собствен проект в шест конкретни стъпки. Ще получите сравнение на водещите инструменти, реални примери от практиката и честен поглед върху ограниченията на технологията.
Ключови факти:
- RAG пазарът расте от $1.85 млрд. (2025, Precedence Research) към $11 млрд. (2030, Grand View Research) при CAGR между 38.4% и 49.1% в зависимост от анализатора
- GPT-4 с RAG постига 0% халюцинации при ракова информация от надежден специализиран източник (CIS), срещу ~40% при конвенционални chatbot-и без RAG, според проучване от 2025 г.. За въпроси извън базата данни, Google-базираните chatbot-и показват 19% халюцинации
- RAG може да се имплементира с 5 реда код — по-бързо и по-евтино от fine-tuning
- Юридическа фирма намалила времето за преглед на договори с 45% чрез RAG
- Правните RAG инструменти все още халюцинират между 17% и 33% от времето
- Vector database съхранение: $0.05–$0.12 за милион вектори (Pinecone, Weaviate, Qdrant)
- Северна Америка държи 36.4% от пазарния дял; водещ сегмент е извличането на документи с 32.4%
- LangChain, LlamaIndex и RAGFlow са безплатни с отворен код
Какво е RAG и защо ви трябва?
RAG (Retrieval-Augmented Generation) е процесът на оптимизиране на резултата на голям езиков модел, така че да референцира авторитетна база от знания извън неговите обучителни данни, преди да генерира отговор. Казано по-просто: вместо LLM-ът да разчита само на това, което е „научил" по време на training-а, RAG му дава достъп до актуални документи, бази данни и вътрешни знания на организацията в реално време.
Представете си разликата между студент, който отговаря на изпит по памет, и такъв, който може да ползва учебник. Паметта е ограничена, остарява и греши. Справочникът е актуален, точен и проверим. Точно тази разлика прави RAG критично важен за практическото приложение на AI в бизнеса.
Проблемът с обикновените LLM-и е конкретен: моделите имат „cutoff" дата на обучение и не знаят нищо, случило се след нея. Освен това те „халюцинират" — генерират убедително звучащи, но неверни факти. В проучване за ракова информация на японски език, публикувано в PubMed (2025), конвенционалните chatbot-и без RAG халюцинират при около 40% от запитванията. GPT-4 с RAG и надеждна специализирана база данни (CIS) постига 0% халюцинации — но само за въпроси, покрити от базата.
RAG разширява възможностите на LLM-ите до специфични домейни или вътрешната база от знания на организацията, без необходимост от преучаване. Технологията е разходоефективна и може да се внедри значително по-бързо от алтернативите. Концепцията е въведена за първи път от Meta (тогава Facebook) в научен доклад от 2020 г..
"Идеята зад RAG е проста: вместо да разчитаме модел да знае всичко наизуст, му даваме достъп до библиотека. Това фундаментално променя начина, по който AI системите работят с информация." — Патрик Люис, главният автор на оригиналния RAG доклад, Meta AI Research
Какво ви трябва за начало с RAG?
Преди да преминете към стъпките, проверете дали разполагате с необходимото:
Инструменти и акаунти:
- Python 3.9+ (за LangChain или LlamaIndex)
- Акаунт в OpenAI, Anthropic или достъп до локален модел (Ollama)
- Акаунт в Pinecone, Weaviate или Qdrant (има безплатни нива)
- Docker (ако ще ползвате RAGFlow)
Необходими знания:
- Базово познаване на Python (ако нямате — вижте нашето ръководство за AI автоматизация без код)
- Разбиране на API заявки (GET/POST)
- Основни концепции за бази данни
Бюджет:
- Минимален старт: $0 (с безплатни нива на LlamaIndex + локален модел)
- Практически проект: $10–50/месец (OpenAI API + vector database)
Очаквано време:
- Прочит на ръководството: 20–25 минути
- Първи работещ прототип: 2–4 часа
- Production-готова система: 1–2 седмици
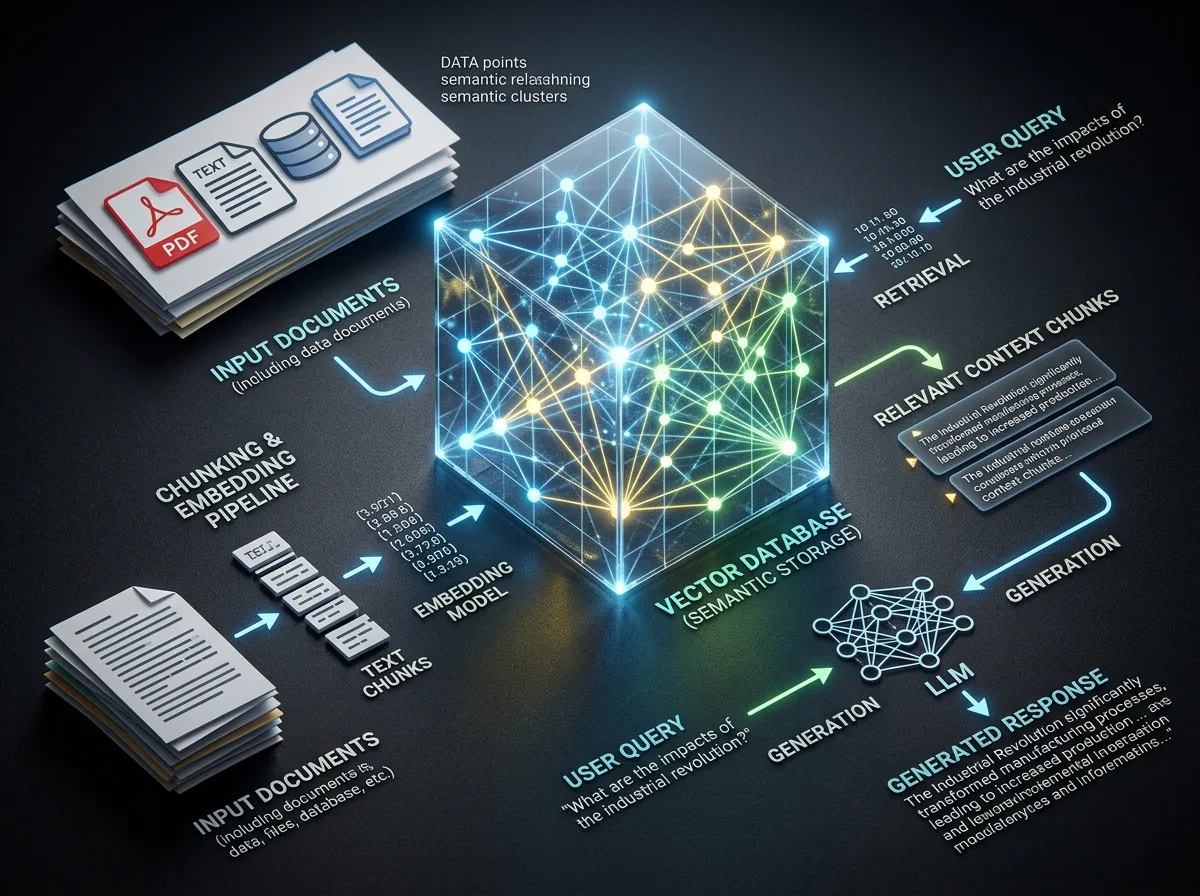
Как работи RAG и какви са 3-те ключови фази?
RAG функционира в три последователни фази — Retrieval (извличане), Augmentation (аугментиране) и Generation (генериране). Всяка фаза има конкретна роля, специфични инструменти и собствени ограничения.
Фаза 1: Retrieval (Извличане)
В тази фаза системата претърсва и извлича фрагменти от информация, релевантни към въпроса на потребителя. В отворена среда тези факти могат да идват от индексирани интернет документи; в затворена корпоративна среда се използва по-тесен набор от вътрешни източници за по-висока сигурност и надеждност.
Данните за позоваване се преобразуват в LLM embedding-и — числови репрезентации под формата на голям векторен простор. RAG може да работи с неструктурирани (текст), полуструктурирани или структурирани данни като графики на знания. Тези embedding-и се съхраняват в vector database, което позволява бързо и точно извличане на документи.
Ограничение: RAG ефективността зависи изцяло от това дали извличащият компонент предоставя правилния контекст. Системите за извличане често се затрудняват с езика на конкретния домейн, което води до липсващи или нерелевантни резултати.
Фаза 2: Augmentation (Аугментиране)
RAG системата създава нов prompt за LLM-а с обогатен контекст от извлечените данни. Този prompt се състои от първоначалния потребителски запит плюс контекстът, върнат от модела за извличане. RAG системите използват различни техники на prompt инженерство за автоматизиране на ефективното създаване на prompt-и.
Ограничение: Дори с точно и релевантно извлечено съдържание, RAG моделите все още могат да произведат халюцинации, генерирайки изходи, които противоречат на извлечената информация. Разбирането как LLM-ите балансират между външни и параметрични знания остава активна изследователска тема.
Фаза 3: Generation (Генериране)
В генеративната фаза LLM-ът извлича от аугментирания prompt и своята вътрешна репрезентация на обучителните данни, за да синтезира отговор, приспособен към конкретния потребител в конкретния момент. Резултатът е по-точен, по-актуален и по-проверим от стандартния LLM изход.
Ограничение: Ограниченията в RAG компонентите могат да причинят халюцинации — или по-точно конфабулации — в генерирания резултат. Системата не е имунизирана срещу грешки, само значително ги намалява.
| Фаза | Какво се случва | Ключов инструмент | Основен риск |
|---|---|---|---|
| Retrieval | Търсене в документи по семантична близост | Vector Database | Нерелевантни резултати |
| Augmentation | Обогатяване на prompt-а с контекст | LLM оркестратор | Неправилно форматиране |
| Generation | Генериране на финален отговор | LLM (GPT-4, Claude) | Остатъчни халюцинации |
RAG срещу Fine-tuning: Кой е по-добър избор?
RAG и fine-tuning решават различни проблеми и изборът между тях зависи от конкретния случай. Fine-tuning преучи модела с нови данни — ефективен е, когато искате да промените стила, тона или специализираните способности на модела. RAG добавя знания в реално време, без да пипа модела.
Практическата разлика е в цената и скоростта. Разработчиците могат да имплементират RAG с толкова малко, колкото пет реда код, което го прави по-бързо и по-евтино от преучаване на модел с допълнителни набори от данни. Fine-tuning изисква GPU ресурси, специализирани данни и значително повече инженерно усилие.
| Критерий | RAG | Fine-tuning |
|---|---|---|
| Цена | $0–50/месец | $500–5000+ за run |
| Скорост | 2–4 часа до прототип | Дни до седмици |
| Актуалност | Реално време | Статична след training |
| Гъвкавост | Висока - смени документи | Ниска - нов training |
| Прозрачност | Цитира източници | Непрозрачен |
| Сложност | Ниска до средна | Висока |
Кога да изберете RAG: Имате нужда от актуална информация (новини, цени, вътрешни документи); искате проследимост на изворите; бюджетът е ограничен; данните се променят често.
Кога да изберете fine-tuning: Искате модел с конкретен стил или тон; работите с много специализиран домейн без добри документи; нямате нужда от актуалност; имате достатъчно качествени training данни.
В повечето бизнес случаи RAG е правилният първи избор. Fine-tuning се добавя по-късно, ако RAG не е достатъчен.
6-стъпков процес за внедряване на RAG
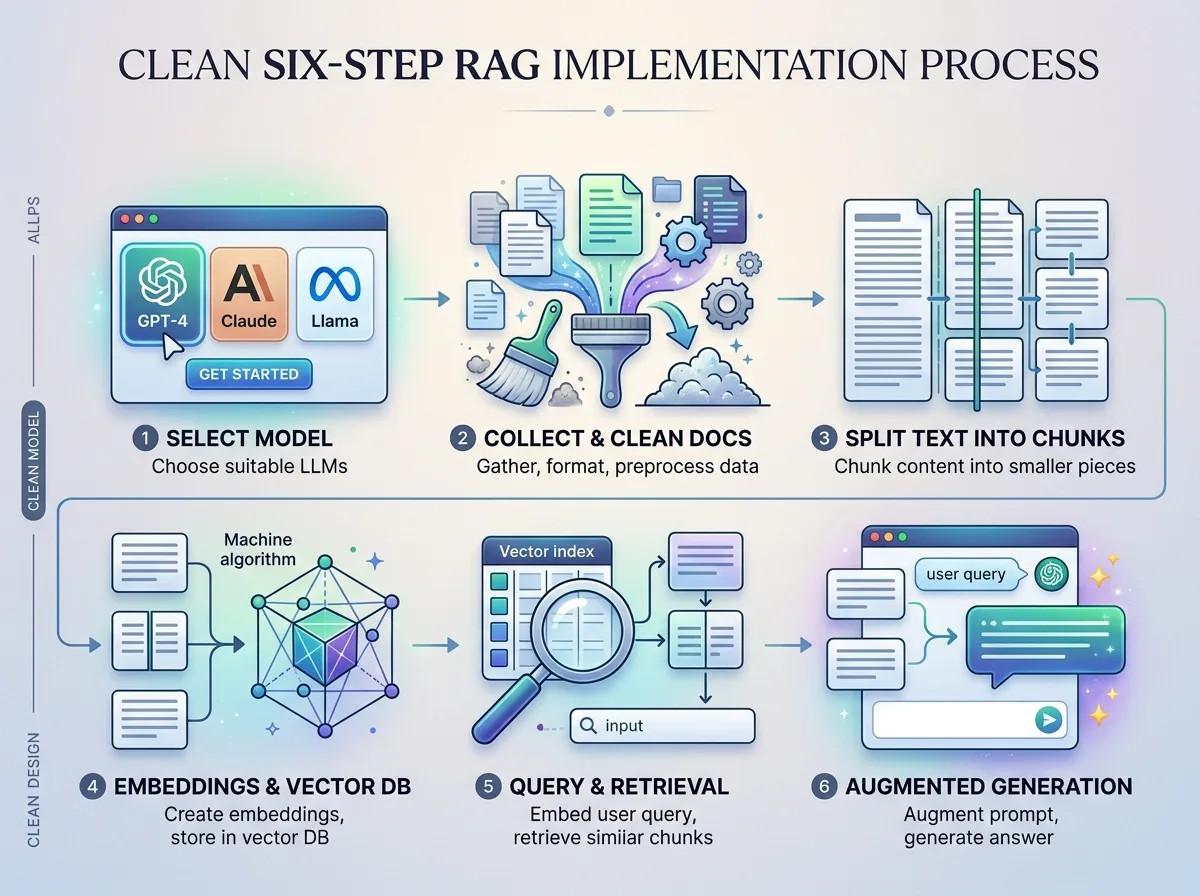
Стъпка 1: Изберете LLM модел
Какво правим: Избираме основния езиков модел, върху който ще работи RAG системата.
Как: LangChain предоставя всеобхватна рамка за оркестриране на целия LLM workflow и предлага абстракции за взаимодействие с различни модели. За начало препоръчваме GPT-4o (OpenAI) или Claude 3.5 Sonnet (Anthropic) за cloud решения, или Llama 3 за локално внедряване.
from langchain_openai import ChatOpenAI
# Инициализиране на LLM модел
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
api_key="вашия-openai-api-key"
)
Очакван резултат: Работеща връзка с LLM, потвърдена с тестов prompt.
Ако не работи: Проверете дали API ключът е валиден и дали имате достатъчен кредит в акаунта.
Типична грешка: Избор на модел с висока температура (temperature > 0.3) за RAG — това увеличава вариативността и халюцинациите. За RAG използвайте temperature=0.
Стъпка 2: Подготовка на данни
Какво правим: Идентифицираме и подготвяме документите, които ще бъдат базата от знания.
Как: Идентифицирайте и получете изходните документи, като се уверите, че са в разбираем за LLM формат — текстови файлове, таблици или PDF. Независимо от изходния формат, всеки документ трябва да бъде преобразуван в текстов файл преди вграждане в vector database. Този процес е известен като ETL (извличане, трансформиране и зареждане).
from langchain_community.document_loaders import PyPDFLoader, DirectoryLoader
# Зареждане на PDF документи от директория
loader = DirectoryLoader(
"./documents/",
glob="**/*.pdf",
loader_cls=PyPDFLoader
)
documents = loader.load()
print(f"Заредени {len(documents)} документа")
Очакван резултат: Списък с Document обекти, готови за обработка.
Ако не работи: Проверете дали PDF файловете не са сканирани изображения — те изискват OCR обработка преди зареждане.
Типична грешка: Включване на документи с ниско качество или остаряло съдържание. Качеството на RAG системата е пряко пропорционално на качеството на документите.
Стъпка 3: Чункване на текст
Какво правим: Разделяме документите на по-малки, семантично свързани части.
Как: Разделянето на текст (chunking) подготвя документите за извличане, като ги парсва и каталогизира в свързани части на базата на отличителни характеристики. Размерът на chunk-а е критичен — твърде малък губи контекст, твърде голям намалява точността на извличане.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Разделяне на текст на chunk-ове
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # символи на chunk
chunk_overlap=200, # припокриване за запазване на контекст
length_function=len
)
chunks = text_splitter.split_documents(documents)
print(f"Създадени {len(chunks)} chunk-а")
Очакван резултат: Списък с по-малки Document обекти с размер около 1000 символа.
Ако не работи: Опитайте с chunk_size=500 за по-кратки документи или 1500 за дълги технически текстове.
Типична грешка: Игнориране на chunk_overlap. Без припокриване, информацията на границата между два chunk-а се губи при извличане.
Стъпка 4: Генериране на embedding-и
Какво правим: Преобразуваме текстовите chunk-ове в числови векторни репрезентации.
Как: Моделите за embedding преобразуват данни в числови репрезентации и ги съхраняват в vector database. Този процес създава библиотека от знания, която генеративните AI модели могат да разберат и претърсват семантично.
from langchain_openai import OpenAIEmbeddings
# Инициализиране на embedding модел
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small",
api_key="вашия-openai-api-key"
)
# Тест на embedding
test_vector = embeddings.embed_query("тестово изречение")
print(f"Размер на вектора: {len(test_vector)} измерения")
Очакван резултат: Вектор с 1536 измерения за text-embedding-3-small.
Ако не работи: Проверете дали имате достатъчен кредит — embedding заявките се таксуват отделно от chat completion.
Типична грешка: Смесване на различни embedding модели при индексиране и при търсене. Трябва да използвате ЕДИН и същ модел за двете операции.
Стъпка 5: Съхранение в Vector Database
Какво правим: Съхраняваме embedding-ите в специализирана база данни за бързо семантично търсене.
Как: Потребителският запит се преобразува в векторна репрезентация и се съпоставя с векторните бази данни. Релевантността се изчислява с помощта на математически векторни изчисления. Доставчиците Pinecone, Weaviate, Zilliz и Qdrant са направили векторното търсене мащабируемо и готово за enterprise употреба, като цените варират между $0.05 и $0.12 за милион вектори.
from langchain_community.vectorstores import Chroma
# Създаване на локален vector store (безплатно за тестване)
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db"
)
print("Vector database създадена успешно")
Очакван резултат: Локална Chroma база данни с всички chunk-ове, готова за търсене.
Ако не работи: За production среда преминете към Pinecone или Qdrant с техните безплатни начални нива.
Типична грешка: Използване на локален vector store в production. Chroma е отлична за разработка, но за реален трафик имате нужда от управляван cloud vector store.
Стъпка 6: Интеграция с LLM
Какво правим: Свързваме vector database с LLM-а, за да завършим RAG pipeline-а.
Как: RAG моделът аугментира потребителския вход чрез добавяне на релевантните извлечени данни в контекст. Тази стъпка използва техники на prompt инженерство за ефективна комуникация с LLM. Аугментираният prompt позволява на LLM-а да генерира точен отговор на потребителските запити.
from langchain.chains import RetrievalQA
# Създаване на RAG chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(
search_kwargs={"k": 4} # брой извличани chunk-ове
),
return_source_documents=True
)
# Тестов запит
result = qa_chain.invoke({"query": "Какви са условията на договора?"})
print(result["result"])
print(f"Използвани {len(result['source_documents'])} документа")
Очакван резултат: Точен отговор, основан на вашите документи, с посочени източници.
Ако не работи: Увеличете k от 4 на 6–8, ако отговорите са непълни. Намалете chunk_size от стъпка 3, ако контекстът е твърде дълъг.
Типична грешка: Пропускане на return_source_documents=True. Без проследяване на изворите не можете да верифицирате точността на отговорите.
Топ RAG инструменти и рамки за 2026
Изборът на правилния RAG инструмент зависи от вашите технически умения, бюджет и специфичните нужди на проекта. Пет инструмента доминират пазара — всеки с различен подход и целева аудитория.
LangChain
LangChain е библиотека с отворен код под MIT лиценз, налична безплатно. Служи като изключително гъвкава рамка, предназначена за изграждане на сложни LLM workflow-и. Превъзхожда се в свързване на множество задачи, интегриране на външни инструменти и управление на разговорна памет.
Силни страни: Огромна екосистема от интеграции (над 100 конектора), активна общност, детайлна документация, поддръжка на AI агенти.
Слабости: По-стръмна крива на учене. Модулярността и гъвкавостта изискват по-дълбоко разбиране на LLM концепции.
Идеален за: Разработчици, които имат нужда от сложни агенти, персонализирани инструменти и потребителски workflow-и.
LlamaIndex
LlamaIndex работи на модел на ценообразуване, основан на използване, с безплатно ниво, включващо 1,000 дневни кредити. Персонализиран е за индексиране и извличане на структурирани и неструктурирани данни, с вградени механизми за запитване и маршрутизатори.
Силни страни: По-нежна крива на учене, по-лесен старт за разработчици, нови в LLM, фокус върху data connectivity.
Слабости: По-ограничена гъвкавост — приоритизира лесна употреба над прецизен контрол.
Идеален за: Разработчици с нужда от напреднали способности за индексиране и извличане, или такива, търсещи бърз старт.
Haystack
Haystack от deepset е безплатен с отворен код, с платени платформи deepset Studio и deepset Cloud. Описван като „универсален нож" на RAG — мощна, модулна рамка с компоненти за извличане на документи, отговаряне на въпроси и обобщение на текст.
Силни страни: Поддържа голямо разнообразие от хранилища на документи, включително Elasticsearch и FAISS. Отлична за сложни приложения за търсене.
Слабости: Само Python — без SDK за JavaScript, Java или други езици. По-стръмна крива на учене от по-леките RAG библиотеки.
Идеален за: Сложни enterprise приложения с множество източници на данни и разнообразни опции за извличане.
RAGFlow
RAGFlow е водещ open-source RAG двигател, предназначен около способностите за дълбоко разбиране на документи. За разлика от много други RAG рамки, превъзхожда в извличане на структурирана информация от сложни документи като PDF, включително таблици. Предлага интуитивен low-code интерфейс за проектиране и конфигуриране на RAG workflow-и.
Силни страни: Визуален конструктор на workflow-и, без-код RAG pipeline-и, отличен за не-разработчици.
Слабости: Изисква Docker за внедряване. По-малко кастомизиране в сравнение с code-first подходите.
Идеален за: Екипи, за които визуалната конфигурация и готовите RAG решения са приоритет.
Dify
Dify е платформа с отворен код за създаване на AI приложения, комбинираща Backend-as-a-Service с LLMOps. Включва висококачествени RAG двигатели, гъвкава AI агент рамка и прост low-code workflow.
Силни страни: Всичко на едно място — RAG, агенти, управление на модели. Лесен за употреба интерфейс.
Слабости: Относително нов на пазара с по-малка екосистема от LangChain.
Идеален за: Екипи, търсещи интегрирано решение за RAG, агенти и управление на модели.
| Инструмент | Цена | Сложност | Идеален за | Лиценз |
|---|---|---|---|---|
| LangChain | Безплатно | Висока | Разработчици, агенти | MIT |
| LlamaIndex | Безплатно / Usage | Средна | RAG начинаещи | MIT |
| Haystack | Безплатно / Cloud | Висока | Enterprise търсене | Apache 2.0 |
| RAGFlow | Безплатно | Ниска | Без-код RAG | Apache 2.0 |
| Dify | Безплатно / Cloud | Ниска | Интегрирани решения | Apache 2.0 |
За повече AI инструменти, подходящи за бизнес автоматизация, вижте нашия преглед на AI инструменти за дизайн и продуктивност.
Реални примери на RAG в действие
RAG не е само теория — технологията вече работи в конкретни индустрии с измерими резултати. Ето пет документирани приложения, включително едно с директна релевантност за България.
Финанси: Автоматизиран анализ в реално време
Финансови аналитици традиционно събират данни от десетки източници за инвестиционни обобщения, доклади за производителност и оценки на риск. RAG автоматизира този процес чрез изтегляне в реално време на пазарни данни, финансови доклади и вътрешни показатели, след което генерира персонализирани анализи. Системата позволява задаване на въпроси на обикновен език и получаване на отговори, теглени от ERP системи, финансови API-та и пазарни хранилища едновременно.
Право: 45% по-бързо разглеждане на договори
Юридическа фирма внедри RAG за подпомагане на проверката на договори, намалявайки времето за преглед на документи с 45% и гарантирайки включването на актуални правни прецеденти. Резултатът е по-бърз краен срок за клиентите и по-ефективен работен процес. Правните екипи използват RAG за съставяне на договори, изследване на прецеденти и извличане на специфични клаузи от хиляди документи.
Важна уговорка: Въпреки подобрението, правните RAG инструменти от LexisNexis и Thomson Reuters все още халюцинират между 17% и 33% от времето, според проучване на Stanford (2025). Правната верификация от специалист остава задължителна.
Здравеопазване: 28% по-бързи клинични решения
Болнична мрежа в Европа тества RAG приложение, интегрирано с диагностична система. Лекарите могат да задават въпроси като „Какви са скорошните лечебни опции за устойчив на лекарства туберкулоз при възрастни пациенти?" — системата извлича последните публикации, филтрирани по релевантност, и генерира кратко обобщение. В ранни тестове това намалило времето до решение с 28% и подобрило диагностичната увереност в сложни случаи.
Релевантност за България: Български болници и медицински центрове могат да внедрят подобни системи с документи на български език — RAG поддържа многоезични среди и може да извлича информация на различни езици, включително български.
Клиентско обслужване: По-умни chatbot-и
RAG подобрява клиентското обслужване, като дава на виртуалните асистенти незабавен достъп до вътрешни документи, история на билети и FAQ. Вместо консервирани отговори, тези асистенти разбират контекст и предоставят релевантна помощ. Резултатът е по-бързо обслужване и по-доволни клиенти — без нужда от постоянна ръчна актуализация на базата от знания.
Образование: Персонализирани учебни асистенти
RAG захранва умни учебни асистенти, даващи на студентите бърза и точна помощ по различни предмети — теглена директно от одобрени образователни материали. Вместо генерични отговори от интернет, AI-ът тегли съдържание от учебници, планове на уроци и бележки от класове, след което го обяснява на езика на студента. Тази технология е приложима и за обучителни платформи на български език.
За повече примери как RAG се вписва в по-широката AI автоматизация за бизнес, вижте нашите практически примери.
Ограничения и предизвикателства на RAG
RAG не е универсално решение и честното разбиране на ограниченията му е критично за успешно внедряване. Три основни предизвикателства стоят пред всяка RAG система.
Халюцинации — намалени, но не елиминирани
Дори с точна и релевантна извлечена информация, RAG моделите все още могат да произведат халюцинации, генерирайки изходи, които противоречат на извлеченото съдържание. Ограниченията в RAG компонентите могат да причинят конфабулации в генерирания резултат. Правните RAG инструменти халюцинират между 17% и 33% от времето — значително по-малко от обикновените LLM-и, но все още достатъчно, за да изискват човешка верификация.
Решение: Използвайте техники на prompt инженерство за смекчаване на халюцинациите. Задължително включвайте return_source_documents=True и верифицирайте критичните отговори спрямо изворите. Регулаторната рамка на EU AI Act изисква прозрачност при AI системи с висок риск — RAG с проследяване на източници улеснява спазването на тези изисквания.
Релевантност на извличане — домейн специфичен проблем
RAG ефективността зависи изцяло от това дали извличащият компонент предоставя правилния контекст. Системите за извличане често се затрудняват с езика на конкретния домейн, което води до липсващи или нерелевантни резултати, когато LLM-ът не извлича ключовите документи.
Решение: Уверете се, че корпусът от документи е чист, актуален и релевантен. Инвестирайте в качествено чункване и подходящ избор на embedding модел за вашия домейн. За специализирани области (медицина, право, финанси) обмислете domain-specific embedding модели.
Операционна сложност — скрити разходи
RAG системите носят операционна и инфраструктурна сложност: управление на vector store, мониторинг на производителност, контрол на данни и проблеми със сигурността. Управляваните vector store-ове таксуват между $0.05 и $0.12 за милион вектори, но реалните разходи включват и API заявки, embedding генериране и инфраструктура.
Решение: Обмислете използването на Model Context Protocol (MCP) за стандартизация на данните в RAG pipeline-а. MCP позволява на RAG системата да има достъп до разнообразни външни източници на данни без необходимост от индивидуализирани интеграции, улеснявайки мащабирането.
- ✓GPT-4 с RAG постига 0% халюцинации при въпроси, покрити от надеждна база данни (проучване за ракова информация, PubMed 2025)
- ✓Внедряване с 5 реда код - без нужда от GPU или специализиран хардуер
- ✓Актуална информация в реално време без преучаване на модела
- ✓Проследяеми отговори с цитирани източници
- ✓Разходоефективен - $0–50/месец срещу $500+ за fine-tuning
- ✓Поддържа многоезични среди, включително български
- ×Халюцинации не са елиминирани - 17–33% в правни системи
- ×Качеството зависи изцяло от качеството на документите
- ×Операционна сложност: vector store, мониторинг, сигурност
- ×Латентност - допълнителна стъпка на извличане забавя отговора
- ×Домейн специфични embedding модели изискват допълнителна настройка
- ×Не подобрява стила или тона на модела - за това е нужен fine-tuning
RAG пазарът и тенденциите за 2026–2030
RAG пазарът е един от най-бързо растящите сегменти в AI индустрията. Оценките за 2025 г. варират: Precedence Research дава $1.85 млрд., а Grand View Research — $1.5 млрд. Прогнозите за 2030 г. сочат към $9.86–11 млрд. при CAGR между 38.4% (MarketsandMarkets) и 49.1% (Grand View Research). До 2035 г. прогнозите варират между $40 и $81 млрд.
Северна Америка държи 36.4% от пазарния дял (2024), следвана от Европа и Азиатско-тихоокеанския регион. Водещият функционален сегмент е извличането на документи с 32.4% от глобалния приход, а водещото приложение е генерирането на съдържание.
Четири ключови тенденции за 2026–2030:
Многомодален RAG: RAG се прилага все по-широко към многомодални случаи на употреба — търсене на изображения, извличане на код, научни изследвания и enterprise разузнаване на знания. Системите вече могат да обработват не само текст, но и таблици, диаграми и мултимедия.
Специализирани RAG решения: Най-активните инвестиционни области включват домейн-специфични RAG стекове за здравеопазване, право и финансови услуги, както и платформи, обвързващи извличане с управление, съотговорствие и сигурна обработка на данни.
On-premises внедряване: Сегментът на локалното внедряване се очаква да расте с най-бърз темп, особено в индустрии със строги регулации — банки, здравеопазване, правителство и отбрана. За организации в тези сектори, приоритизиращи поверителност на данните, on-premises RAG е препоръчаният избор.
Интеграция с AI агенти: През март 2025 г. OpenAI пусна нови инструменти за изграждане на агенти с вградена оптимизация на запитване. Microsoft представи CoRAG (Chain-of-Retrieval Augmented Generation), позволяващ итеративно извличане и разсъждаване вместо едностъпково извличане. За повече за AI агентите и тяхната роля в съвременните системи — вижте нашия детайлен преглед.
Как да изберете правилния RAG инструмент за вас?
Изборът на RAG инструмент зависи от три ключови фактора: технически умения, специфика на проекта и бюджет. Следвайте това практично ръководство:
Ако сте разработчик с опит в Python и имате нужда от максимална гъвкавост: → Изберете LangChain. Предлага най-богата екосистема от интеграции, поддържа сложни агенти и персонализирани workflow-и. Стартирайте с безплатния open-source пакет.
Ако сте разработчик, нов в LLM, и искате бърз старт: → Изберете LlamaIndex. По-нежна крива на учене, фокус върху data connectivity и RAG workflow-и. Безплатното ниво с 1,000 дневни кредити е достатъчно за прототипиране.
Ако имате нужда от визуална конфигурация без писане на код: → Изберете RAGFlow или Dify. Визуален конструктор на workflow-и, без-код pipeline-и, готови за enterprise употреба. Изисква Docker за локално внедряване.
Ако изграждате сложна enterprise система за търсене: → Изберете Haystack. Модулна архитектура, поддръжка на Elasticsearch и FAISS, отлична за сложни приложения с множество източници.
Критерии за финален избор:
| Критерий | Въпрос, който да си зададете |
|---|---|
| Сложност | Имате ли Python разработчик в екипа? |
| Поддръжка | Нужна ли ви е enterprise поддръжка? |
| Интеграции | Какви бази данни и API-та трябва да свържете? |
| Цена | Какъв е месечният бюджет за инфраструктура? |
| Мащабируемост | Очаквате ли над 100,000 запитвания/месец? |
За Bulgarian-specific контекст: всички изброени инструменти поддържат многоезични embedding модели и могат да работят с документи на български език. Конкретни данни за официална поддръжка на български от водещите компании не са налични, но практическото внедряване с български документи е напълно осъществимо чрез настройка на модела и базата от знания.
Най-честите грешки и как да ги избегнете
1. Лошо качество на документите
Най-честата причина за неработещ RAG е не техническият проблем, а лошото качество на входните данни. Ако документите са остарели, непълни или с ниско качество, RAG системата ще генерира неточни отговори дори при перфектна техническа имплементация. Решение: инвестирайте в ETL процес, преди да индексирате каквото и да е.
2. Неправилен размер на chunk-овете
Твърде малки chunk-ове (под 200 символа) губят контекст; твърде големи (над 2000 символа) намаляват точността на извличане. Оптималният размер зависи от типа документи — за технически документи 800–1200 символа, за правни текстове 500–800 символа. Тествайте с различни размери и измервайте точността.
3. Смесване на embedding модели
Ако индексирате с text-embedding-3-small и търсите с text-embedding-ada-002, резултатите ще са безсмислени. Трябва да използвате ЕДИН и същ embedding модел за целия pipeline. Документирайте кой модел използвате и не го сменяйте без пълно преиндексиране.
4. Игнориране на проследяването на източници
Без return_source_documents=True не можете да верифицирате откъде идва информацията. Това е особено критично в регулирани индустрии (медицина, право, финанси), където EU AI Act изисква прозрачност и обяснимост.
5. Deployment без мониторинг
RAG системите деградират с времето — документите остаряват, embedding моделите се обновяват, потребителските нужди се променят. Внедрете мониторинг от първия ден: следете процента на успешни отговори, латентността и честотата на „не знам" отговори.
Съвети за напреднали
1. Hybrid search за по-добра точност Комбинирайте семантично търсене (embedding similarity) с ключово търсене (BM25). Hybrid search подобрява точността на извличане, особено за специализирани термини и собствени имена, които embedding моделите обработват по-слабо.
2. Re-ranking на резултатите След първоначалното извличане приложете cross-encoder re-ranker (напр. Cohere Rerank или BGE Reranker), за да пресортирате резултатите по реална релевантност. Това значително подобрява качеството на финалния отговор.
3. Query expansion Преди търсене разширете потребителския запит с LLM — генерирайте 3–5 варианта на въпроса и търсете с всички. Обединете резултатите с Reciprocal Rank Fusion (RRF). Техниката подобрява recall при неясни или кратки запитвания.
4. Metadata filtering Добавете metadata към chunk-овете (дата, автор, тип документ, отдел) и филтрирайте при търсене. Вместо да търсите в цялата база, ограничете до релевантния subset — по-бързо и по-точно.
5. Интеграция с AI агенти Комбинирайте RAG с AI агенти за многостъпкови задачи. Агентът може да реши кога да извлича от документи, кога да използва инструменти и кога да поиска допълнителна информация от потребителя — CoRAG от Microsoft е пример за тази архитектура.
Често задавани въпроси
Защо RAG е по-добър от fine-tuning за повечето случаи?+
Колко струва внедряването на RAG?+
Мога ли да ползвам RAG с български текст?+
Какво е vector database и защо е нужна?+
Как да намаля халюцинациите в моята RAG система?+
Колко сложно е да внедря RAG без програмен опит?+
Заключение: Обобщение и следващи стъпки
RAG е доказана, практична технология, която решава конкретен проблем: LLM-ите знаят много, но не знаят вашите данни. С шестте стъпки в това ръководство можете да изградите работеща RAG система в рамките на един работен ден.
Ключовите изводи: изберете правилния инструмент за вашите умения (LangChain за разработчици, RAGFlow за без-код подход), инвестирайте в качеството на документите преди техническата имплементация, и никога не пропускайте проследяването на източници. RAG намалява халюцинациите значително, но не ги елиминира — човешката верификация остава необходима в критични приложения.
Конкретна следваща стъпка: Инсталирайте LangChain и LlamaIndex (pip install langchain llama-index), изберете пет документа от вашата организация и изградете първия прототип по стъпките в това ръководство. Резултатът ще ви покаже дали RAG решава вашия конкретен проблем — преди да инвестирате в production инфраструктура.
За по-задълбочено разбиране на prompt техниките, използвани в Augmentation фазата, прочетете нашето ръководство за prompt инженерство. Ако искате да видите как RAG се вписва в по-широки AI автоматизационни системи, разгледайте практическите примери за AI автоматизация.
Допълнителни ресурси
- Оригиналният RAG доклад от Meta (2020) — Lewis et al., арXiv
- RAG Survey (2023) — Comprehensive overview на RAG техниките
- IBM: What is RAG? — Достъпно обяснение с примери
- NVIDIA: What is RAG? — Технически детайли и use cases
- AWS: What is RAG? — Cloud имплементация
- LangChain документация — Официален getting started guide
- LlamaIndex документация — RAG tutorials и примери
- RAGFlow GitHub — Open-source RAG engine с визуален интерфейс
- Stanford: Legal RAG Hallucinations Study (2025) — Изследване на ограниченията в правния контекст
Основател на CyberNinjas.ai и Кибер Хора. Пише за AI инструменти, новини и практически ръководства.
Още статии
 AI Ръководства17 мин.
AI Ръководства17 мин.ChatGPT Memory и Projects: персонален AI асистент [2026]
Изградете персонален AI асистент с ChatGPT Memory и Projects стъпка по стъпка — пълен setup за 30 минути, 5 use cases, FAQ и съвети за начинаещи [2026].
 AI Ръководства21 мин.
AI Ръководства21 мин.Claude Code + Antigravity: от нула до AI оркестратор [2026]
Claude Code + Google Antigravity IDE — пълен наръчник: настройка, CLI команди, MCP сървъри, Skills, Hooks и агентна оркестрация стъпка по стъпка [2026].
 AI Ръководства14 мин.
AI Ръководства14 мин.Claude Code + NotebookLM чрез MCP: пълен наръчник [2026]
Claude Code + NotebookLM чрез MCP — пълен наръчник за настройка стъпка по стъпка. Нулеви халюцинации, автономно проучване и citation-backed отговори [2026].