
GPT-5.5 преглед: benchmarks vs Claude 4.7 и Gemini [2026]
GPT-5.5 излезе на 23.04.2026 — новият flagship на OpenAI с 82.7% на Terminal-Bench. Пълен преглед: цени, benchmarks и сравнение с Claude и Gemini в 2026.
Накратко: OpenAI пусна GPT-5.5 на 23 април 2026 г. — само 3 дни преди тази статия. Новият flagship модел постига 82.7% на Terminal-Bench 2.0, поддържа 1M tokens context window и излиза в два варианта (стандартен и Pro). Моделът е подходящ за developers, engineering екипи и enterprise клиенти, които искат автономен агент за дълги coding сесии и computer use — но при удвоена цена ($5/$30 на милион tokens) и най-високия hallucination rate сред flagship моделите.
Ключови факти:
- Дата на пускане: 23 април 2026 г. (ChatGPT + Codex), API от 24 април
- Кодово име: "Spud"
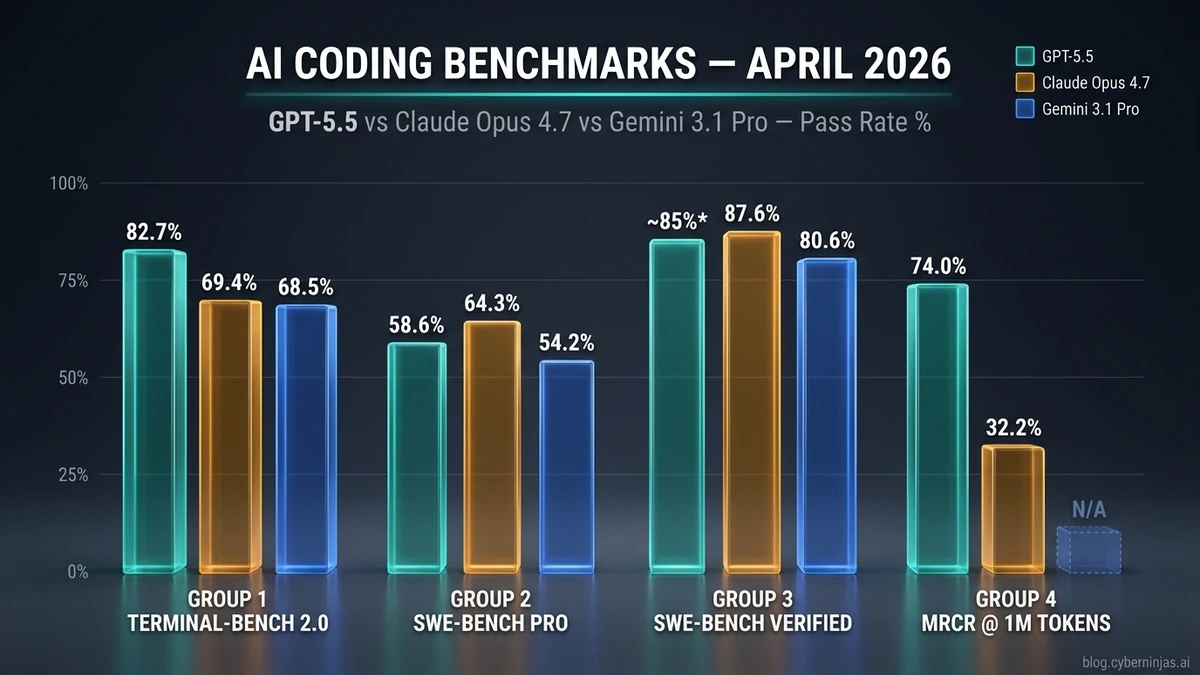
- Terminal-Bench 2.0: 82.7% — лидер срещу Claude Opus 4.7 (69.4%) и Gemini 3.1 Pro (68.5%)
- SWE-bench Pro: 58.6% — изостава от Claude Opus 4.7 (64.3%)
- MRCR v2 при 1M tokens: 74.0% (Claude Opus 4.7: 32.2%)
- API цена: $5/$30 на милион tokens — двойно повече от GPT-5.4
- Context window: 1 050 000 tokens (922K input + 128K output)
- Hallucination rate (AA-Omniscience): 86% — най-високият сред flagship моделите
Какво е GPT-5.5 и какъв проблем решава?
GPT-5.5 е най-новият flagship модел на OpenAI, пуснат на 23 април 2026 г. — едва 6 седмици след предшественика GPT-5.4 (5 март 2026). Според OpenAI president Greg Brockman, моделът е "нов клас интелигентност" и "по-бърз и по-проницателен мислител с по-малко tokens спрямо нещо като 5.4". TechCrunch описва позиционирането като стъпка към OpenAI "super app" — унифициран продукт, в който ChatGPT, Codex и AI browser работят заедно за enterprise клиенти.
GPT-5.5 е large language model с обединена архитектура за text и image input (output все още text-only според OpenAI API документацията) и 1 милион tokens context window. Поддръжката за audio и video е описана от community reviewers, но не е потвърдена в публичната API спецификация към момента на писане. Моделът е достъпен в два варианта — стандартен (GPT-5.5 Thinking) и Pro — и поддържа пет нива на reasoning effort: xhigh, high, medium, low и non-reasoning. За първи път в продуктовата линия на OpenAI, моделът е обучен да използва около 40% по-малко output tokens за същата задача в Codex, което свежда ефективното увеличение на разходите до около 20% спрямо удвоената per-token тарифа.
Проблемът, който GPT-5.5 решава, е дълбочината на агентската автономия в реална работна среда. Предишните flagship модели — включително GPT-5 и Claude Opus 4.7 — се справят добре с дискретни задачи, но често губят coherence на 10+ tool calls или при работа с monorepos над 500K tokens. GPT-5.5 въвежда изрично "long-horizon agentic" дизайн, който поддържа структурирано планиране, самоверификация и cross-tool оркестрация без human-in-the-loop. На практика това означава, че можете да дадете на агента "обработи този CSV, направи график, попълни spreadsheet и качи презентация" — и моделът да изпълни цялата верига сам.
За потребителите в България, които вече използват ChatGPT Plus или Codex през chatgpt.com, GPT-5.5 е автоматична замяна на GPT-5.4 без допълнителна такса. За тези, които работят с API-то директно, новата цена е значително увеличение, което изисква повторна калкулация на разходите при по-стари workloads.
GPT-5.5: Ключови функции на новия flagship на OpenAI
GPT-5.5 носи няколко конкретни подобрения, които директно влияят на developer и enterprise работните потоци.
Обединена архитектура за text и image
GPT-5.5 обработва text и image input в обща forward-pass архитектура, без отделни encoder-и за всяка модалност. Това намалява latency при cross-modal reasoning и подобрява UI code generation от screenshots. Според Lushbinary developer guide, архитектурата позволява multi-file refactoring с реални UI клонинги като output. Native обработка на audio и video е спомената в community reviews като предстояща функция, но официалната API спецификация в момента изброява text и image като поддържани input типове и text като output.
Пет нива на reasoning effort
Моделът въвежда пет дискретни нива на reasoning effort — xhigh, high, medium, low и non-reasoning — които позволяват точно контролиране на cost-to-intelligence съотношението. Според Jake Handy от Handy AI, "GPT-5.5 на medium effort постига същия резултат на Artificial Analysis Intelligence Index като Claude Opus 4.7 на max effort, но при една четвърт от цената".
Codex с in-app browser
Codex получава in-app browser с поддръжка за screenshot capture, click + type автоматизация и iterative refinement върху rendered UI. Потребителите могат да оставят коментари директно върху страницата, за да дадат точни инструкции на агента. Codex поддържа 400 000 tokens context window в ChatGPT и до 1M tokens в API.
Task-budgets и Trusted Access for Cyber
GPT-5.5 въвежда нова програма Trusted Access for Cyber за верифицирани security researchers. Моделът е класифициран като "High" capability в OpenAI Preparedness Framework за биология/химия и cybersecurity, което води до по-строги контроли срещу неоторизирана употреба.
Какво не може GPT-5.5
- Hallucination rate 86% на AA-Omniscience — най-високият сред flagship моделите. Това означава, че когато моделът не знае нещо, рядко казва "не знам" — вместо това генерира уверено, но грешно
- SWE-bench Pro 58.6% — изостава от Claude Opus 4.7 (64.3%) на real-world GitHub issue resolution
- TTFT ~3 секунди — почти 6 пъти по-бавен от Opus 4.7 (~0.5s) за първи token, което прави GPT-5.5 по-малко подходящ за interactive pair-programming
- OPQA регресия — на скрит вътрешен benchmark с 20 реални OpenAI engineering задачи моделът постига 1.7% срещу 5.8% за GPT-5.3 Codex (-70% спрямо предшественика)
- Self-harm safety регресия — score пада от 0.977 на 0.937 спрямо GPT-5.4
- AISI universal jailbreak — британският AI Security Institute намери универсален jailbreak за 6 часа red-teaming, преди release
Как работи GPT-5.5 в ChatGPT и Codex
GPT-5.5 е достъпен през три основни канала — ChatGPT, Codex и API — със значими разлики между тях.
Стъпка 1: Изберете канал за достъп
- ChatGPT (Plus/Pro/Business/Enterprise): моделът се избира директно от dropdown менюто. GPT-5.5 Pro е достъпен само за Pro, Business и Enterprise планове
- Codex (Plus, Pro, Business, Enterprise, Edu, Go плановете): достъпен с 400K context window, fast mode за 1.5× скорост при 2.5× credit cost
- OpenAI API: model ID
gpt-5.5илиgpt-5.5-pro, поддръжка на batch и flex tier с 50% отстъпка
Стъпка 2: Конфигурирайте reasoning effort
За API използването изглежда така:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.5",
reasoning={"effort": "xhigh"},
input=[
{"role": "user", "content": "Рефакторирай този модул без да чупиш тестовете."}
],
)
xhigh дава най-добро качество на сложни задачи, но има значително по-висок latency (до 55 секунди до първи token според Artificial Analysis). За production endpoint-и, които изискват бърз response, medium или high са по-практичен default избор.
Стъпка 3: Използвайте Codex browser за UI задачи
Новият Codex in-app browser отваря локален development server и позволява на агента да click-ва, screenshot-ира и тества промените си в реално време. Браузър режимът се активира от Codex таб в ChatGPT (Plus, Pro, Business, Enterprise, Edu, Go планове) — потребителят отваря локалния URL, дава задача в естествен език и наблюдава как агентът оперира страницата. Точният CLI syntax зависи от версията на Codex client; за актуални команди препоръчваме официалния OpenAI Codex changelog.
Типичен workflow: агентът отваря страницата, прави screenshot, идентифицира проблема, прилага CSS или markup поправка, презарежда и верифицира визуално. Това е първата OpenAI имплементация на пълен closed-loop visual debugging.
Стъпка 4: Ограничете разходите с batch API
За задачи, които не изискват real-time response (eval suites, historical reprocessing), използвайте batch tier:
batch = client.batches.create(
input_file_id=file.id,
endpoint="/v1/responses",
completion_window="24h",
)
Batch processing намалява разходите наполовина — $2.50/$15 вместо стандартните $5/$30 на милион tokens. За екипи, които пускат хиляди оценки нощем, това е разликата между 1000 и 2000 евро месечно.
GPT-5.5: За кого е подходящ новият модел (и за кого не е)
GPT-5.5 е оптимизиран за дълги, многоетапни agentic задачи и computer use, но има конкретни сценарии, в които конкурентите се справят по-добре.
Подходящ за:
- Senior developers, които управляват long-running agent workflows в Codex или собствен orchestration layer
- DevOps инженери за CI/CD автоматизация, log analysis и infrastructure-as-code generation
- Data engineers за multi-step ETL pipelines с CSV → analysis → spreadsheet → presentation вериги
- Enterprise architects, които работят с monorepo над 500K tokens и се нуждаят от long-context coherence
- Researchers в bioinformatics и mathematics — според официалното съобщение на OpenAI, моделът е допринесъл за нов proof относно Ramsey numbers, проверен в Lean (community верификация в момента в ход)
По-малко подходящ за:
- Журналисти, юристи и медицински специалисти — 86% hallucination rate го прави опасен за citation-heavy работа без external fact-check layer
- Потребители с малък бюджет — Gemini 3.1 Pro струва $1.25/$10 за същата input/output комбинация
- Interactive pair-programming в IDE — Claude Opus 4.7 има 6× по-бърз TTFT и е по-подходящ за Cursor/Windsurf workflows
- Single-file fix-it задачи — Claude Opus 4.7 води на SWE-bench Verified (87.6% срещу ~85% за GPT-5.5) и SWE-bench Pro (64.3% vs 58.6%)
- ✓Лидер на agentic benchmarks — 82.7% Terminal-Bench 2.0 (+13.3pp над Claude Opus 4.7)
- ✓Най-добра long-context coherence — 74.0% MRCR v2 при 1M tokens (Opus: 32.2%)
- ✓40% по-малко output tokens на същата задача в Codex — намалява effective cost
- ✓Native omnimodal архитектура — text, image, audio, video в един forward pass
- ✓Пет нива на reasoning effort за точен cost/quality tradeoff
- ✓Browser автоматизация в Codex с screenshot + click + verify loop
- ×Двойна API цена спрямо GPT-5.4 — $5/$30 vs $2.50/$15 за милион tokens
- ×86% hallucination rate на AA-Omniscience — опасен за citation-heavy работа
- ×Изостава от Claude Opus 4.7 на SWE-bench Verified/Pro и MCP-Atlas
- ×TTFT ~3 секунди — 6× по-бавен от Opus 4.7 за interactive coding
- ×Self-harm safety score регресира от 0.977 на 0.937
- ×AISI намери universal jailbreak за 6 часа red-teaming преди release
GPT-5.5 vs Claude Opus 4.7 vs Gemini 3.1 Pro: коя е истината?
Сравнението на трите водещи модели за кодиране към края на април 2026 показва ясна картина: никой не печели по всички категории. Изборът зависи от типа задача, бюджета и толерантността към hallucinations.
Coding benchmarks — head-to-head
| Benchmark | GPT-5.5 | Claude 4.7 | Gemini 3.1 Pro |
|---|---|---|---|
| SWE-bench Verified | ~85%* | 87.6% | 80.6% |
| SWE-bench Pro | 58.6% | 64.3% | 54.2% |
| Terminal-Bench 2.0 | 82.7% | 69.4% | 68.5% |
| MCP-Atlas | 75.3% | 79.1% | 73.9% |
| MRCR v2 при 1M | 74.0% | 32.2% | няма |
| Input цена / 1M tok | $5.00 | $5.00 | $1.25 |
| Output цена / 1M tok | $30.00 | $25.00 | $10.00 |
| TTFT (interactive) | ~3 сек | ~0.5 сек | варира |
*GPT-5.5 SWE-bench Verified не е официално публикуван от OpenAI — стойност от трети страни (Apiyi, Lushbinary).
Анализ: кога кой модел печели на benchmark-ите
Claude Opus 4.7 е по-добрият избор за real-world GitHub issues — на SWE-bench Verified постига 87.6% срещу около 85% за GPT-5.5. Anthropic отбелязва, че разликата е дори по-широка след изключване на problems с memorization concerns. На SWE-bench Pro (по-трудната, индустриална версия с 4 езика), Claude Opus 4.7 води с 5.7 процентни пункта.
GPT-5.5 печели категорично на agentic CLI задачи — на Terminal-Bench 2.0 моделът е с 13.3 процентни пункта пред Opus 4.7. Според VentureBeat анализа, "GPT-5.5 е no potato" — наистина бие Anthropic, макар и тясно. На long-context retrieval (MRCR v2 при 1M tokens), разликата е огромна — 74% за GPT-5.5 срещу 32.2% за Opus 4.7. Това прави GPT-5.5 единственият надежден избор за анализ на големи monorepos.
Gemini 3.1 Pro е най-евтиният — около 4 пъти по-евтин от другите двама на input и 3 пъти на output. На coding benchmarks обикновено заема трето място, но при правилен harness (TongAgents framework) постига 80.2% на Terminal-Bench 2.0 — близо до GPT-5.5. За проекти с голям обем batch evaluation или R&D експерименти, разходната ефективност го прави най-логичния избор.
Експертно мнение от enterprise клиент
"Това, което виждаме при 5.5 — мисля, че е наистина важно за силно регулирана институция — е качеството на отговорите, но също и наистина впечатляваща устойчивост срещу hallucinations. Една банка трябва да има много висока точност, така че това става критично, и наблюдаваме реална стъпка напред с този модел." — Leigh-Ann Russell, CIO и Global Head of Engineering, Bank of New York
Според Fortune, Bank of New York тества GPT-5.5 в regulated banking workflows (не специфично coding) успоредно с конкуриращи модели на Anthropic и управлява над 220 AI use cases във вътрешната си production среда. Russell цитира hallucination resistance и качеството на отговорите като ключов differentiator — критерии, които пряко се пренасят в coding context-и, изискващи висока фактическа точност (например automated документация, compliance проверки или regulated SDK генериране).
Разликата в hallucination rate
Един факт, който често се пропуска в маркетинговите материали: на AA-Omniscience benchmark (независимата оценка от Artificial Analysis), GPT-5.5 постига 57% accuracy — най-високият от всички flagship модели — но и 86% hallucination rate. За сравнение: Claude Opus 4.7 има 36% hallucination rate, а Gemini 3.1 Pro — 50%. AA-Omniscience дефинира hallucination като "процент на грешни отговори, в които моделът confabulates вместо да се откаже". На практика: когато GPT-5.5 не знае нещо, рядко казва "не знам" — генерира уверено, но грешно. За legal, medical и regulatory задачи това е значителен риск.
Цена и наличност на GPT-5.5 в България
GPT-5.5 е достъпен в България без регионални ограничения чрез ChatGPT и API. Плановете и цените са идентични с глобалните, но плащанията в евро са възможни директно от януари 2026 след влизането на България в еврозоната.
ChatGPT абонаменти (за крайни потребители)
| План | Цена | Достъп до GPT-5.5 |
|---|---|---|
| Free | €0 | Лимитиран (10 съобщения / 5 часа) |
| Go | €4/мес | 2× Free лимити |
| Plus | €20/мес | Стандартни лимити, всички модели |
| Pro | €200/мес | + Thinking mode, GPT-5.5 Pro вариант |
| Business | €25/seat/мес | Shared workspaces |
| Enterprise | По договаряне | SOC 2, SAML SSO, audit logs |
Цените са от OpenAI pricing страницата, достъпна и за БГ потребители. Plus планът ($20/€20 на месец) е най-балансираният вариант за повечето български developers и freelancers.
API цени (за разработчици)
API цените са в USD без конверсия (стандарт за AI инструменти):
- Стандарт: $5 input / $30 output на милион tokens
- Cached input: $0.50 на милион tokens
- GPT-5.5 Pro: $30 input / $180 output на милион tokens
- Batch API (50% отстъпка): $2.50 / $15 на милион tokens
- Flex tier (50% отстъпка): $2.50 / $15, но с variable latency
- Priority tier (2.5×): $12.50 / $75 за гарантиран throughput
За prompts над 272 000 input tokens, цените се умножават с 2× за input и 1.5× за output до края на сесията. Това е важен детайл за приложения, които обработват дълги документи в едно API повикване.
Българска практика — кога коя цена има смисъл
За БГ developer с типично API натоварване (около 50 000 reasoning tokens дневно при medium effort, 50/50 input/output ratio, USD→EUR курс ~0.93), реалният разход е приблизително €30-50 на месец. За малък SaaS startup със 100 активни потребители и средно по 10 заявки дневно при същите assumptions — приблизително €400-700 на месец. Точният разход зависи силно от reasoning effort, prompt caching adoption и съотношението input/output tokens — препоръчваме A/B тест върху реални production prompt-и преди дългосрочно ангажиране. Тези числа са значително по-високи от ерата на GPT-5.4 и оправдават миграция към batch API за всички async задачи.
Практически съвети за работа с GPT-5.5
Тези пет правила идват от ранните benchmark резултати и community feedback в първите дни след пускането.
- Включи external fact-check layer за всеки factual output. Заради 86% hallucination rate, не разчитайте на GPT-5.5 за citations, regulatory references или medical claims без второ мнение от друг модел или източник.
- Използвайте
mediumreasoning effort като default. Според Handy AI, на medium effort GPT-5.5 постига същата интелигентност като Opus 4.7 на max — при една четвърт от цената.xhighизползвайте само за наистина сложни математически или научни задачи. - Маршрутирайте задачите към подходящия модел. Дайте на GPT-5.5 терминал и agentic задачи плюс long-context monorepo анализ. Дайте на Claude Opus 4.7 single-file fix-it bug-ове и code review. Дайте на Gemini 3.1 Pro batch evaluation и R&D експерименти, където цената има значение.
- Капнете output tokens с hard limit. Reasoning models могат да консумират хиляди internal tokens, преди да дадат финален отговор. Задайте
max_output_tokens=8000като default и увеличавайте само, когато наистина трябва. - Активирайте prompt caching за repeated context. Cached input е $0.50/M вместо $5/M — десеткратна икономия за приложения, които изпращат същия system prompt много пъти. Използвайте
prompt_cache_keyза маркиране на повтарящ се префикс.

Често задавани въпроси за GPT-5.5
Кога излезе GPT-5.5 и какъв е codename-ът?+
Колко струва GPT-5.5 в България?+
GPT-5.5 по-добър ли е от Claude Opus 4.7 за кодиране?+
Какво означава „86% hallucination rate“ на GPT-5.5?+
Какви са основните нови функции в GPT-5.5?+
GPT-5.5 поддържа ли български език?+
GPT-5.5: Какво докладват early adopters в първите 72 часа
В първите 72 часа след пускането, независимите тестери и community разработчици споделиха няколко конкретни наблюдения, които допълват официалните benchmark числа.
Simon Willison, който поддържа своя характерен "pelican on a bicycle" SVG benchmark, докладва, че GPT-5.5 на default reasoning effort произвежда сравнимо качество с GPT-5.4. Едва на xhigh effort моделът показва по-CSS-heavy и по-структуриран output — но за сметка на 9 322 reasoning tokens срещу 39 на default режим. Това потвърждава, че qualitative gain е концентриран на висок effort, не на baseline.
Jake Handy от Handy AI документира конкретен пример за cost-equivalence: "GPT-5.5 на medium effort постига същия Artificial Analysis Intelligence Index като Claude Opus 4.7 на max effort, но при около една четвърт от цената". Тази находка е валидна за организации, които вече плащат на Anthropic Opus максимална тарифа.
Karo Zieminski в независим обзор за citation reliability определя GPT-5.5 като "най-слабия flagship за citation-heavy задачи" — посочвайки 86%-овия AA-Omniscience confabulation rate като дисквалифициращ за академични, правни и медицински workflows без external verification layer. Същата критика отстоява и UK AI Security Institute, който намери universal jailbreak за 6 часа red-teaming и не успя да валидира финалната конфигурация преди release.
В обобщение: early adopter signals потвърждават посоката на benchmark данните — GPT-5.5 е силен за agentic и long-context задачи, слаб за factual recall и premium-priced. Без масова hands-on верификация от community, читателите трябва да третират ранните benchmark резултати като конкретен сигнал, не като крайна истина.
GPT-5.5: Заключение: заслужава ли си новият модел на OpenAI?
GPT-5.5 е най-добрият избор за дълги agentic workflows и long-context monorepo задачи, но не е универсален победител. Моделът има реални предимства — лидер на Terminal-Bench 2.0, изключителна 1M tokens coherence и подобрена token efficiency — но идва с три значими компромиса: най-високият hallucination rate сред flagship моделите, удвоена per-token цена и значителен latency спрямо Claude Opus 4.7.
За повечето практически случаи в България, рационалният избор е multi-model маршрутизация: GPT-5.5 за Codex agent loops и компютърна автоматизация, Claude Opus 4.7 за code review и интерактивно pair-programming, Gemini 3.1 Pro за cost-sensitive batch processing. Слепият upgrade от GPT-5.4 към GPT-5.5 не е оправдан за всички workloads — per-token цената се удвоява, а ефективното увеличение на разходите остава около 20% само ако претенциите за token efficiency се потвърдят на вашите конкретни prompt-и. Препоръчваме A/B тест преди постоянна миграция.
Ако искате да направите по-дълбоко сравнение между трите водещи модела, прочетете нашия пълен преглед на Claude Opus 4.7, пълния преглед на Gemini 3.1 Pro или сравнението ChatGPT vs Claude vs Gemini за по-широк контекст.
Допълнителни ресурси
- OpenAI официален анонс: Introducing GPT-5.5
- System Card: GPT-5.5 Deployment Safety Hub
- API документация: GPT-5.5 Model Page
- Pricing: OpenAI API Pricing
- Independent benchmark: Artificial Analysis — GPT-5.5
- Side-by-side анализ: LLM-Stats — GPT-5.5 vs Claude Opus 4.7
Основател на CyberNinjas.ai и Кибер Хора. Пише за AI инструменти, новини и практически ръководства.
Още статии

DeepSeek V4 преглед: benchmarks vs Claude и GPT-5.5 [2026]
DeepSeek V4 Pro излезе на 24.04.2026 — open-source MoE с 1.6T параметри и 1M контекст. Преглед: benchmarks срещу Claude Opus 4.7, GPT-5.5 и Gemini в 2026.

Grok 4.3 преглед: benchmarks vs Claude и GPT-5.5 [2026]
Grok 4.3 от xAI с 1M контекст, силен скок при agentic задачи и Custom Voices гласово клониране — преглед, цени и сравнение с Claude Sonnet и GPT-5.5 [2026]

GPT Image 2: сравнение с Midjourney, Flux 2 и Imagen [2026]
Тествахме GPT Image 2 срещу Midjourney V8, Flux 2 и Nano Banana 2 — цени, бенчмарки, Thinking режим с web search и какво ново носи OpenAI през април 2026