
Qwen 3.6-27B: dense модел и benchmarks vs Claude [2026]
Qwen 3.6-27B пуснат на 22.04.2026 от Alibaba — моделът изравнява или надминава Claude 4.5 Opus на три теста. SWE-bench, GPQA, MMLU числа и БГ контекст.
Накратко: Qwen 3.6-27B е нов dense open-weight модел на Alibaba, публикуван на 22 април 2026 г. на Hugging Face Hub и ModelScope под Apache 2.0 лиценз. Моделът изравнява или надминава Claude 4.5 Opus на три ключови теста (Terminal-Bench 2.0, GPQA Diamond, HMMT Feb 25), въпреки че е почти десетократно по-малък и open-weight, и надминава по-голямия си брат Qwen 3.6-35B-A3B на практически всички бенчмаркове.
Ключови факти: Qwen 3.6-27B — release дата 22.04.2026. 27 милиарда parameters (dense, не MoE). Native context 262 144 tokens, extensible до 1 010 000 чрез YaRN. Apache 2.0 лиценз. SWE-bench Verified — 77.2 (Claude 4.5 Opus: 80.9). GPQA Diamond — 87.8 (бие Claude 4.5 Opus: 87.0). Terminal-Bench 2.0 — 59.3 (тие с Claude 4.5 Opus: 59.3). LiveCodeBench v6 — 83.9. AIME26 — 94.1. Multi-modal с vision encoder.
Какво се случи в Qwen екосистемата днес?
Qwen 3.6-27B беше публикуван на 22 април 2026 г. на Hugging Face Hub и ModelScope като пореден open-weight член на серията Qwen 3.6. Това пускане завършва интензивен месец за Alibaba — на 2 април дойде Qwen3.6-Plus (proprietary flagship), на 17 април — Qwen3.6-35B-A3B (MoE с 3B активни parameters), а на 20 април — Qwen3.6-Max-Preview (закрит flagship).
Qwen 3.6-27B е dense моделът — без Mixture-of-Experts архитектурата на 35B-A3B варианта. Това е важно за deployment: dense модел се хоства по-предсказуемо на стандартен GPU клъстер, без routing overhead и без необходимост от специализиран MoE inference engine.
В официалното GitHub хранилище Qwen Team описват модела като "Flagship-Level Coding in a 27B Dense Model" — формулировка, която се потвърждава от benchmark числата по-долу.
Защо Qwen 3.6-27B е важна крачка за open-source?
Qwen 3.6-27B демонстрира конкретен принцип: добре проектиран dense модел с 27 милиарда parameters може да се доближи до възможностите на затворен flagship като Claude 4.5 Opus, който е значително по-голям. За екипи, които не могат да си позволят proprietary API цените или предпочитат self-hosted deployment поради regulatory изисквания, това е практическо open-source решение, което вече е достъпно днес.
Apache 2.0 лицензът е особено важен. За разлика от custom лицензията на Llama (с 700M MAU cap) или custom условията на DeepSeek, Apache 2.0 дава пълна commercial свобода — включително модификация, дистрибуция и интеграция в платени продукти без royalty задължения.
Хибридната архитектура зад модела съчетава Gated DeltaNet (linear attention) с Gated Attention в съотношение 3:1 — три DeltaNet блока на всеки четвърти стандартен attention блок. Linear attention намалява квадратичната complexity на класическия attention механизъм до линейна, което прави native 262K контекста изпълним без експлозия в memory usage.
Технически спецификации на Qwen 3.6-27B
Според официалния model card на Hugging Face, Qwen 3.6-27B използва:
- Параметри: 27 милиарда (dense)
- Layers: 64
- Hidden dimension: 5120
- FFN intermediate dimension: 17 408
- Token embedding (padded): 248 320
- Attention pattern: 16 × (3 × Gated DeltaNet → FFN + 1 × Gated Attention → FFN)
- Native context: 262 144 tokens
- Extended context (YaRN): до 1 010 000 tokens
- Training: Multi-token prediction (MTP), pre-training + post-training
- Vision encoder: да (multi-modal text/image/video)
- License: Apache 2.0
Препоръчаните sampling параметри от Qwen Team: за thinking mode (general) — temperature 1.0, top_p 0.95, top_k 20. За coding — temperature 0.6 за повече детерминистично поведение. За instruct mode без reasoning — temperature 0.7, top_p 0.80.
Deployment е поддържан през SGLang и vLLM (production-grade), с Hugging Face Transformers за по-малки workloads. Fine-tuning е възможен чрез UnSloth, Swift и Llama-Factory.
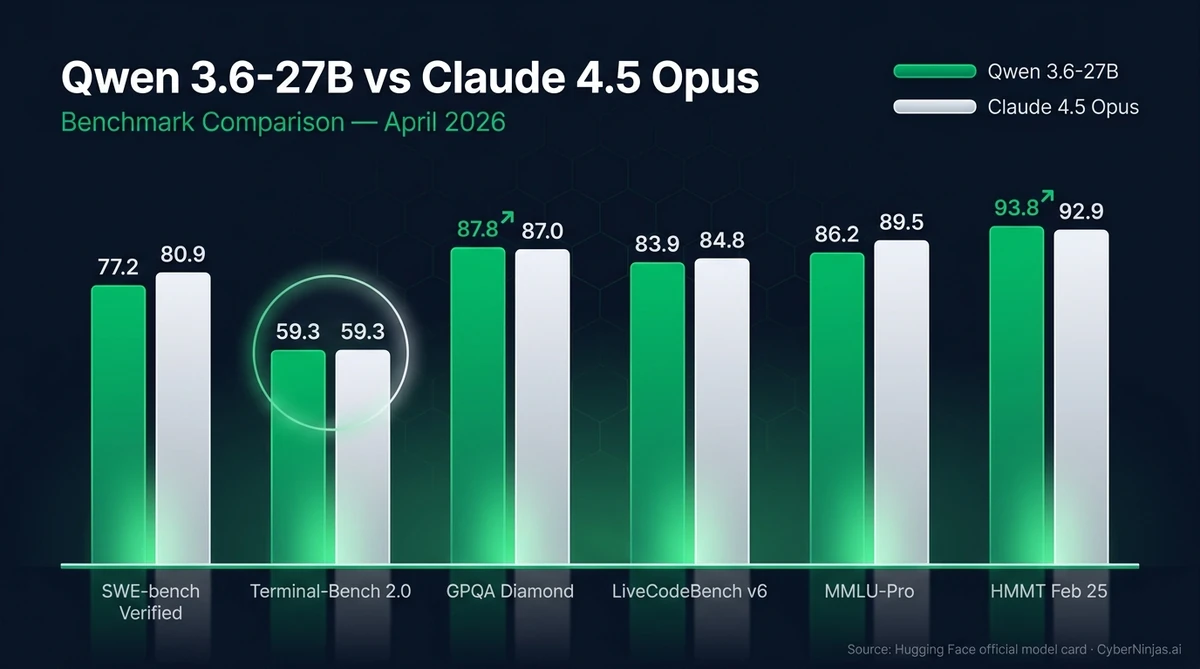
Бенчмаркове: Qwen 3.6-27B срещу Claude 4.5 Opus
Тук са официалните числа от model card документа, които включват директно сравнение с Claude 4.5 Opus и предходния Qwen 3.5-27B.
| Benchmark | Qwen 3.6-27B | Qwen 3.5-27B | Claude 4.5 Opus |
|---|---|---|---|
| SWE-bench Verified | 77.2 | 75.0 | 80.9 |
| SWE-bench Pro | 53.5 | 51.2 | 57.1 |
| Terminal-Bench 2.0 | 59.3 | 41.6 | 59.3 |
| LiveCodeBench v6 | 83.9 | 80.7 | 84.8 |
| GPQA Diamond | 87.8 | 85.5 | 87.0 |
| MMLU-Pro | 86.2 | 86.1 | 89.5 |
| AIME26 | 94.1 | 92.6 | 95.1 |
| HMMT Feb 25 | 93.8 | 92.0 | 92.9 |
Три резултата заслужават специално внимание. Terminal-Bench 2.0 (тест за agentic shell задачи) — Qwen 3.6-27B завършва на 59.3 точки, точно колкото Claude 4.5 Opus, и с почти 18 точки по-добре от предишния Qwen 3.5-27B. GPQA Diamond (graduate-level science questions) — 87.8 срещу 87.0 за Claude. HMMT Feb 25 (Harvard-MIT Math Tournament февруари) — 93.8 срещу 92.9.
На останалите тестове Qwen 3.6-27B остава на 1-3 percentage points от Claude 4.5 Opus, при това като open-weight модел, който можете да свалите и хоствате локално. Vision benchmark резултатите също са силни — MMMU 82.9 и V* (Visual Agent) 94.7.
Сравнение с open-source класа
Qwen 3.6-27B не е сам в 27-35B сегмента. Конкурентите включват:
| Модел | Параметри | SWE-bench | GPQA | License |
|---|---|---|---|---|
| Qwen 3.6-27B | 27B dense | 77.2 | 87.8 | Apache 2.0 |
| Qwen 3.6-35B-A3B | 35B / 3B активни | 73.4 | 86.0 | Apache 2.0 |
| Gemma 4 31B | 31B dense | 52.0 | 84.3 | Apache 2.0 |
| DeepSeek V4 | ~1T (очаква се) | 83.7 | ~88 | Custom |
| Llama 4-Behemoth | 2T MoE | ~75 | ~85 | Meta custom (700M MAU cap) |
Според сравнителен анализ на Lushbinary, април 2026 е "the most competitive month in open-source AI history" — шест големи лаборатории шипват модели в това време. Уникалното предимство на Qwen 3.6-27B в тази арена: dense архитектура (за разлика от MoE сложността), Apache 2.0 (за разлика от custom лицензията на Meta) и benchmark резултати на ниво на (или по-високи от) флагшипи с 10-30 пъти по-голяма изчислителна мощ.
- ✓Apache 2.0 лиценз — пълна commercial свобода без royalty
- ✓Dense архитектура — предсказуем GPU deployment без MoE routing complexity
- ✓Бие или тие Claude 4.5 Opus на Terminal-Bench, GPQA, HMMT Feb 25
- ✓Native 262K контекст, разширим до 1M чрез YaRN
- ✓Multi-modal с vision encoder включен
- ✓SGLang и vLLM production deployment поддръжка
- ×27B все още изисква multi-GPU setup за full precision
- ×Изостава с 1-3 точки от Claude 4.5 Opus на повечето text benchmarks
- ×Vision benchmarks са по-слаби от dedicated VLM модели
- ×Apache 2.0 не покрива training данни — възможни рискове, свързани с тренировъчните данни
- ×Без официален hosted API в EU към момента на публикуване
- ×Sampling настройките са критични — грешен top_p чупи качеството

Реакции и анализи в общността
Реакциите в developer общността са свързани главно с практическото приложение. На Hugging Face темата, отворена от потребителя m-ric месеци преди пускането, 27B dense вариантът беше най-чаканият модел в неофициалното community гласуване — повече гласове от 9B и 14B вариантите, които някои очакваха за consumer GPU.
Нагласите в индустрията се концентрират върху един въпрос: дали open-weight моделите достигат точката, в която proprietary флагшипите вече не оправдават премиум цената за определени enterprise use cases. Sebastian Raschka в подробния си LLM Architecture Gallery документира как Qwen3 серията използва хибридни MoE и dense варианти — същата архитектурна посока, която Qwen 3.6-27B доразвива.
Qwen Team официално коментират в GitHub хранилището:
"Qwen3.6 delivers substantial upgrades, particularly in agentic coding. The model now handles front-end workflows and repository-level reasoning with greater fluency and precision." — Qwen Team, Alibaba Group (от официалния README на Qwen3.6)
Дискусионна точка остава напускането на Junyang Lin (бивш Qwen tech lead, който напусна Alibaba през март 2026 г. според VentureBeat). Качеството на пусканията след това подсказва, че екипът продължава да изпълнява, но дългосрочната траектория на Qwen остава отворен въпрос.
Как Qwen 3.6-27B засяга българските разработчици?
Qwen 3.6-27B отваря конкретна възможност за български стартъпи, които искат AI capabilities без зависимост от чужд API доставчик. Apache 2.0 лицензът означава, че можете да направите fine-tuning на модела върху собствените си данни, да го интегрирате в платен продукт и да не плащате royalty на Alibaba.
Конкретни сценарии за БГ разработчиците:
- Self-hosted coding assistant — Qwen 3.6-27B на собствен GPU клъстер може да замени GitHub Copilot за екипи, чувствителни към data sovereignty. SWE-bench 77.2 е достатъчен за автоматизация на routine refactoring задачи.
- Локален RAG за документи на български — multi-modal capabilities + 262K контекст позволяват обработка на големи български документни корпуси без data leakage към external API.
- Регулиран сектор (банкиране, здравеопазване) — за БГ организации с GDPR ограничения и EU AI Act compliance изисквания, on-premises модел като Qwen 3.6-27B премахва трета страна от потока на данни.
За cost сравнение: AWS g5.12xlarge (4× A10G 24GB) струва около $5.67/час и е достатъчен за production inference на Qwen 3.6-27B с quantization. При сегашните цени това е около €4 950 на месец при 24/7 uptime — съпоставимо с разходите за enterprise Claude API за малки до средни workloads.
Какво следва за Qwen екосистемата?
Qwen Team анонсира continued release cadence в официалното GitHub хранилище. Следващите стъпки включват разширена Qwen 3.6 линия с допълнителни open-weight варианти, продължаваща работа върху proprietary Qwen 3.6-Max-Preview за hosted API и потенциално следващото поколение Qwen 3.7 в Q3-Q4 2026.
В по-широката open-source конкуренция, очакваните пускания през следващите седмици включват DeepSeek V4 (потвърден от Reuters като "weeks away") и потенциално нови варианти от Mistral. Април 2026 вероятно ще се запомни като месецът, в който open-source AI стана конкурентоспособен на frontier ниво за по-широка категория задачи, не само на narrow benchmarks.
Дългосрочно, Qwen 3.6-27B е важно доказателство за концепцията: добре проектиран dense модел може да достигне frontier performance в специфични области. Следващите месеци ще покажат дали тази формула се мащабира към 100B+ dense модели или остава sweet spot в 20-40B сегмента.
Често задавани въпроси за Qwen 3.6-27B
Кога е пуснат Qwen 3.6-27B и къде е достъпен?+
Каква е разликата между Qwen 3.6-27B и Qwen 3.6-35B-A3B?+
Какъв hardware ми трябва, за да хоствам Qwen 3.6-27B локално?+
Може ли Qwen 3.6-27B да замени Claude 4.5 Opus?+
Поддържа ли Qwen 3.6-27B български език?+
Какво включва multi-modal вариантът на Qwen 3.6-27B?+
Заключение: какво научихме
Qwen 3.6-27B потвърждава тенденцията от април 2026 г.: open-weight моделите достигат frontier performance в коректно дефинирани сегменти. Apache 2.0 + dense архитектура + native 262K контекст + benchmark резултати на ниво на Claude 4.5 Opus е комбинация, която отваря реални production пътища за екипи, ограничени от cost или privacy изисквания.
Конкретното решение — дали да мигрирате workload от proprietary API към Qwen 3.6-27B — зависи от вашия специфичен use case. SWE-heavy automation, agentic shell задачи и graduate-level reasoning са силните страни. Vision-heavy и mission-critical workloads все още могат да изискват proprietary alternatives.
За читатели, които следят open-source AI ландшафта, препоръчваме анализа на Gemma 4 и защо open-source AI моделите имат значение. За директно сравнение с Claude flagship — вижте пълния преглед на Claude Opus 4.7.
Допълнителни ресурси
Основател на CyberNinjas.ai и Кибер Хора. Пише за AI инструменти, новини и практически ръководства.
Още статии

Изкуствен интелект в училище: какво се променя [2026]
Изкуствен интелект в училище от първи клас — какво предвижда внесеният законопроект, какво вече предложи МОН и кога влизат новите правила у нас през 2026

Gemini 3.6 Flash: AI агент, който сам ползва браузъра [2026]
Gemini 3.6 Flash излезе на 21 юли 2026 г. с вградена функция computer use — какво точно прави моделът сам на екрана, колко струва и какво значи за България

AI в колата: ЕС задължи камерите да следят шофьора [2026]
От 7 юли 2026 г. всеки нов автомобил в ЕС следи погледа на шофьора. Вижте как точно работи AI в колата, записва ли данни и какво означава това за България