
Обучаване на custom AI модел: Пълно ръководство за 2026
Обучаване на custom AI модел: fine-tuning, LoRA и training от нула. Пълно 8-стъпково ръководство с цени, код и реални примери за GPT-4o, Llama и Vertex AI.
Накратко: В това ръководство ще научите как да обучите собствен custom AI модел — от избора на метод и подготовката на данни до стартирането на training job и оценката на резултатите. Следвайки осемте стъпки по-долу, ще можете да стартирате първия си fine-tuning проект още днес, дори без дълбоки технически познания.
Ключови факти:
- Специализираните модели могат да бъдат до 1000 пъти по-бързи и по-евтини от универсалните, според Builder.io
- Fine-tuning на GPT-4o в OpenAI струва $25 за милион training tokens (февруари 2026)
- GPT-4o Mini fine-tuning предлагаше безплатен trial (2M tokens/ден) — проверете актуалните цени на OpenAI за текущи условия
- Fine-tuning на Llama 3.1 8B в Amazon Bedrock струва $0.004 за 1000 tokens
- Обучаването на frontier модел от нула (GPT-4 ниво) струва между $50M–$200M, според Epoch AI
- Mistral Forge беше анонсиран на NVIDIA GTC, март 2026 като платформа за fine-tuning с open-weight модели
- За успешен fine-tuning са необходими минимум 100–1000 висококачествени примера
- Hugging Face предлага безплатен open-source достъп до хиляди pre-trained модели
Какво е обучаването на custom AI модел и защо е важно?
Обучаването на custom AI модел е процесът, при който вземате съществуващ или нов AI модел и го адаптирате към специфичните нужди на вашия бизнес или приложение. За разлика от универсалните модели като ChatGPT, които са обучени да отговарят на всичко, специализираният модел е фокусиран върху конкретна задача — например анализ на юридически документи, поддръжка на клиенти или медицинска диагностика.
Разликата в производителността е измерима. Специализираните модели могат да бъдат до 1000 пъти по-бързи и по-евтини от универсалните при конкретна задача. Причината е проста: универсалният модел трябва да "мисли" в много посоки, докато специализираният е оптимизиран за един тип проблем.
Практическите приложения обхващат почти всяка индустрия. В customer support компаниите обучават модели върху собствените си FAQ и история на разговори, за да получат chatbot, който отговаря точно като техния екип. В медицината и правото специализираните модели анализират документи с точност, която универсалните модели не могат да постигнат без допълнителен контекст.
За български бизнеси обучаването на custom модел решава и езиковия проблем. Универсалните модели са обучени предимно на английски данни. Модел, fine-tuned върху български текстове от вашата индустрия, ще разбира специфичния жаргон, правните термини или медицинската терминология на български — нещо, което стандартните модели правят по-слабо.
Какво ви трябва за обучаване на custom AI модел?
Преди да стартирате, проверете дали разполагате с необходимото:
Инструменти и акаунти:
- Акаунт в OpenAI (за GPT fine-tuning) или Google Cloud (за Vertex AI)
- Python 3.8+ инсталиран локално (за Hugging Face подход)
- Достъп до Google Colab (безплатно, за GPU compute)
Данни:
- Минимум 100 примера за fine-tuning (препоръчително 500–1000)
- Данните трябва да са в структуриран формат (JSONL за OpenAI, CSV/JSON за Vertex AI)
- Почистени данни без дубликати и противоречия
Бюджет:
- Минимален старт: $0 (GPT-4o Mini free trial или Hugging Face)
- Малък проект (100–500 примера): $10–$100
- Среден проект (1000+ примера): $100–$500
Технически познания:
- Базово познаване на Python (за Hugging Face) — ако нямате, използвайте OpenAI или Vertex AI с UI
- Разбиране на JSON формат за подготовка на данни
Очаквано време:
- Подготовка на данни: 2–5 дни (най-важната стъпка)
- Стартиране на training job: 1–4 часа
- Оценка и итерация: 1–3 дни

Три метода за адаптиране на езикови модели: Fine-tuning, LoRA и Training from Scratch
Обучаването на custom AI модел не е един метод — има три основни подхода, всеки с различна цена, сложност и резултат. Изборът на правилния метод е първото критично решение.
Fine-tuning (Supervised Fine-tuning)
Fine-tuning адаптира съществуващ pre-trained модел, като го обучава върху ваши специфични примери. Моделът вече "знае" езика и общите концепции — вие само го насочвате към вашата конкретна задача. Изисква 100–1000+ висококачествени примера за ефективно обучаване.
Процесът работи така: подавате двойки "вход → очакван изход" и моделът коригира своите тегла, за да произвежда по-точни резултати за вашия use case. Това е най-популярният метод за бизнес приложения, защото балансира цена и резултат.
LoRA (Low-Rank Adaptation)
LoRA е parameter-efficient метод за fine-tuning, който обновява само малък процент от теглата на модела. Вместо да промени всички милиарди параметри, LoRA добавя малки "адаптерни" матрици към ключови слоеве. Резултатът: значително по-малко памет и изчислителни ресурси при сравнима производителност.
LoRA е особено подходящ, когато работите с по-голям open-source модел (Llama, Mistral) на собствен hardware или cloud GPU. Hugging Face поддържа LoRA чрез библиотеката PEFT (Parameter-Efficient Fine-Tuning). Ако бюджетът ви е ограничен, започнете с LoRA — ако не работи там, пълният fine-tuning рядко ще реши проблема.
Training from Scratch
Обучаването от нула означава изграждане на нов модел без да използвате pre-trained тегла. Това изисква огромно количество данни и изчислителни ресурси. Обучаването на GPT-4 ниво модел (175B+ параметри) струва между $50M–$200M, а на Llama 3 ниво — около $25M.
Mistral Forge, анонсиран на NVIDIA GTC през март 2026, е новата платформа, която прави fine-tuning с open-weight модели достъпен за enterprise организации с proprietary данни. Това е опция само за компании с много специфични нужди и значителен бюджет.
"Fine-tuning не е само за гигантите — с правилните данни, дори малък модел може да надмине GPT-4 в конкретен домейн." — Андрей Карпати, бивш Director of AI в Tesla и OpenAI
| Критерий | Fine-tuning | LoRA | От нула |
|---|---|---|---|
| Данни нужни | 100–1000 примера | 50–500 примера | Милиони примера |
| Цена (малък проект) | $10–$100 | $5–$50 | $25M+ |
| Технич. сложност | Ниска–средна | Средна | Много висока |
| Памет (GPU) | Висока | Ниска–средна | Изключително висока |
| Контрол | Частичен | Частичен | Пълен |
| Кога да използвате | Специализация на GPT/Llama | Ограничен бюджет/GPU | Proprietary архитектура |
8 стъпки за обучаване на custom AI модел от нулата
Следващите осем стъпки покриват пълния процес на обучаване на custom AI модел — от идеята до работещия продукт.
Стъпка 1: Дефинирайте проблема
Какво правим: Определяме точно какво трябва да прави моделът.
Как: Запишете конкретна задача в едно изречение. Например: "Моделът трябва да класифицира входящи имейли от клиенти в категории: технически проблем, въпрос за цена, жалба, комплимент." Опитът да решите твърде много едновременно води до по-слаби резултати — фокусирайте се върху един use case.
Очакван резултат: Ясна дефиниция на входа (какво подавате на модела) и изхода (какво очаквате да върне).
Ако не работи: Ако не можете да опишете задачата в едно изречение, разбийте я на по-малки подзадачи и обучете отделен модел за всяка.
Стъпка 2: Подготговоре данните
Какво правим: Събираме и почистваме training данните.
Как: Съберете данни, релевантни за вашия проблем — потребителски взаимодействия, transaction logs, документи, текст. След събирането приложете cleaning процес: премахнете дубликати, коригирайте несъотговорствия, нормализирайте форматите. Разделете данните на три части: 70% training, 15% validation, 15% test.
Очакван резултат: Структуриран dataset с минимум 100 примера (препоръчително 500+), без дубликати и с консистентен формат.
Ако не работи: Ако нямате достатъчно данни, разгледайте RAG (Retrieval-Augmented Generation) като алтернатива — RAG не изисква training, а използва вашите документи директно при inference.
Стъпка 3: Изберете базов модел
Какво правим: Избираме pre-trained модел, върху който ще правим fine-tuning.
Как: Ако вече използвате OpenAI в продукта си, изберете GPT-4o или GPT-4o Mini. Ако искате open-source решение с пълен контрол, изберете Llama 3.1 8B или Mistral 7B. За enterprise с AWS инфраструктура — Amazon Bedrock с Llama 3.1. Прочетете нашето сравнение на AI модели за по-детайлен анализ.
Очакван резултат: Избран базов модел с ясно разбиране на цената и ограниченията му.
Ако не работи: Ако моделът не постига добри резултати след fine-tuning, проблемът е най-вероятно в данните, не в избора на модел.
Стъпка 4: Форматирайте данните
Какво правим: Конвертираме данните в формата, изискван от платформата.
Как: За OpenAI fine-tuning използвайте JSONL формат. Всеки ред е отделен JSON обект с conversation структура. Ето примерен JSONL файл:
{"messages": [{"role": "system", "content": "Ти си асистент за клиентска поддръжка на онлайн магазин."}, {"role": "user", "content": "Кога ще пристигне поръчката ми #12345?"}, {"role": "assistant", "content": "Поръчка #12345 е изпратена на 15 март и се очаква да пристигне до 18 март. Можете да проследите пратката с номер BG123456789."}]}
{"messages": [{"role": "system", "content": "Ти си асистент за клиентска поддръжка на онлайн магазин."}, {"role": "user", "content": "Искам да върна продукт."}, {"role": "assistant", "content": "Разбира се! Можете да върнете всеки продукт до 30 дни след покупката. Попълнете формуляра за връщане на нашия сайт и ще получите пълно възстановяване в рамките на 5 работни дни."}]}
{"messages": [{"role": "system", "content": "Ти си асистент за клиентска поддръжка на онлайн магазин."}, {"role": "user", "content": "Продуктът е повреден."}, {"role": "assistant", "content": "Съжаляваме за неудобството! Изпратете снимка на повредата на support@shop.bg и ще ви изпратим нов продукт безплатно в рамките на 2 работни дни."}]}
Очакван резултат: Валиден JSONL файл, който преминава валидацията на OpenAI (можете да проверите с openai tools fine_tunes.prepare_data).
Ако не работи: Проверете дали всеки ред е валиден JSON с онлайн JSON validator. Честа грешка е trailing comma или неправилно escape на специални символи.
Стъпка 5: Конфигурирайте параметрите
Какво правим: Задаваме hyperparameters за training процеса.
Как: За начинаещи препоръчваме да оставите OpenAI да избере параметрите автоматично. Ако искате ръчна конфигурация, ключовите параметри са: n_epochs (брой пъти да преминете през данните — обикновено 3–5), learning_rate_multiplier (скоростта на учене — оставете на default 1.0 за начало), batch_size (брой примери на стъпка — оставете на auto). Включете системния prompt, който е работил най-добре преди fine-tuning-а, в training примерите.
Очакван резултат: Конфигуриран training job, готов за стартиране.
Ако не работи: Ако моделът се обучава прекалено бавно или резултатите са лоши, намалете learning_rate_multiplier на 0.5.
Стъпка 6: Обучете модела
Какво правим: Стартираме training job-а и изчакваме завършването му.
Как: В OpenAI Platform отидете на Fine-tuning → Create и качете JSONL файла. Изберете базов модел, конфигурирайте параметрите и натиснете "Create". Training job-ът ще се появи в списъка с status "running". Процесът за 500 примера отнема обикновено 20–60 минути. Можете да следите прогреса в реално време чрез dashboard-а или API.
Очакван резултат: Завършен training job с уникален model ID (например ft:gpt-4o-2024-08-06:your-org:custom-name:abc123).
Ако не работи: Ако job-ът fail-ва, проверете валидността на JSONL файла и дали имате достатъчен кредит в акаунта си.
Стъпка 7: Оценете производителността
Какво правим: Тестваме модела върху данни, които не е виждал по време на training.
Как: Използвайте test set-а (15% от данните, заделени в Стъпка 2). Изчислете accuracy, precision, recall и F1 score. За класификационни задачи F1 score над 0.85 е добър резултат. Сравнете резултатите с базовия модел без fine-tuning, за да видите реалното подобрение.
Очакван резултат: Числени метрики, показващи подобрение спрямо базовия модел.
Ако не работи: Ако метриките са слаби, проблемът е най-вероятно в качеството на данните — върнете се към Стъпка 2.
Стъпка 8: Итерирайте и оптимизирайте
Какво правим: Подобряваме модела въз основа на резултатите от оценката.
Как: Ако моделът не постига желаните резултати, не преминавайте директно към full fine-tuning. Започнете с LoRA или добавете повече висококачествени примери. Ако LoRA не работи, full fine-tuning рядко ще реши проблема — по-вероятно е данните да имат нужда от подобрение. Добавете примери за случаите, в които моделът греши, и стартирайте нов training job.
Очакван резултат: Подобрен модел с по-високи метрики след всяка итерация.
Колко струва обучаването на custom AI модел през 2026?
Цените за обучаване на custom AI модел варират значително в зависимост от платформата, модела и обема на данните. Ето актуалните цени от март 2026:
| Платформа | Цена training | Цена inference | Безплатен план | Най-подходящ за |
|---|---|---|---|---|
| OpenAI GPT-4o | $25/млн tokens | $3.75 input / $15 output /млн | Имаше free trial (проверете актуалност) | Компании вече ползващи OpenAI |
| OpenAI GPT-4o Mini | $0 (free trial) | По-ниска от GPT-4o | Имаше free trial (проверете) | Начинаещи и малки проекти |
| Amazon Bedrock | $0.004–0.005/1000 tokens | Custom Model Units: $0.157/мин | Не | AWS-базирани организации |
| Google Vertex AI | Pay-per-use (~$1–10) | Зависи от GPU/TPU часове | Free tier с ограничения | Enterprise с BigQuery данни |
| Hugging Face | Безплатно (само compute) | Плащате собствен compute | Да - напълно | Разработчици с технич. умения |
| RunPod GPU | $2–32/час GPU | N/A (self-hosted) | Не | LoRA training на open-source модели |
| Together AI | Custom pricing | Зависи от модела | Не | Fine-tuning на open-source модели |
| Mistral Forge | Custom (enterprise) | N/A | Не | Fine-tuning на enterprise модели |
Примерни цени за три сценария:
- Малък проект (100 примера, GPT-4o Mini): ~$0 (в рамките на free trial)
- Среден проект (1000 примера, GPT-4o): ~$25–$50 за training + inference разходи
- Голям проект (10 000 примера, GPT-4o): ~$250–$500 за training
OpenAI Fine-tuning API: Как да обучите custom AI модел?
OpenAI предлага най-достъпния path за fine-tuning на GPT модели с минимална техническа сложност. Процесът се извършва изцяло чрез уеб интерфейс или API.
Стъпки за стартиране:
- Регистрирайте се на platform.openai.com и добавете платежен метод
- Отидете на Fine-tuning в лявото меню
- Качете вашия JSONL файл (минимум 10 примера, препоръчително 50+)
- Изберете базов модел:
gpt-4o-2024-08-06илиgpt-4o-mini-2024-07-18 - Натиснете Create fine-tuning job
- Следете прогреса в dashboard-а — ще получите имейл при завършване
Тестване на модела след training:
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="ft:gpt-4o-2024-08-06:your-org:custom-name:abc123",
messages=[
{"role": "system", "content": "Ти си асистент за клиентска поддръжка."},
{"role": "user", "content": "Кога ще пристигне поръчката ми?"}
]
)
print(response.choices[0].message.content)
Цената за inference на fine-tuned GPT-4o е $3.75 за милион input tokens и $15 за милион output tokens. За сравнение, стандартният GPT-4o струва $2.50/$10 — fine-tuned версията е малко по-скъпа, но значително по-точна за вашата задача.
Google Vertex AI: Enterprise платформа за създаване на собствен AI
Google Vertex AI предлага по-гъвкав подход към custom training с поддръжка на множество frameworks — TensorFlow, PyTorch и XGBoost. Платформата е особено подходяща за организации, които вече използват Google Cloud и имат данни в BigQuery.
Vertex AI предлага три основни опции: AutoML (минимален код, автоматична конфигурация), Serverless training (динамично провизиониране на ресурси) и Dedicated clusters (за мащабни проекти). За начинаещи AutoML е най-лесният вход — качвате данните, избирате задачата и платформата конфигурира всичко автоматично.
Предимството пред OpenAI е пълният контрол върху инфраструктурата и по-добрата интеграция с enterprise системи. Недостатъкът е по-стръмната крива на учене — Vertex AI изисква разбиране на Google Cloud концепции. За детайлно ръководство вижте нашата статия за Vertex AI Studio.
Кога да изберете Vertex AI пред OpenAI:
- Данните ви са в BigQuery или Google Cloud Storage
- Нуждаете се от GDPR-compliant обработка в EU региони
- Искате да fine-tune модели, различни от GPT (включително собствени TensorFlow модели)
- Имате нужда от dedicated compute с гарантирани ресурси
Hugging Face: Безплатна платформа за fine-tuning на AI модели
Hugging Face е de facto стандарт за open-source AI development с над 500 000 pre-trained модела в Hub-а. Fine-tuning е безплатен — плащате само за compute (собствен хардуер или cloud GPU).
Примерен Python код за fine-tuning с Hugging Face Transformers:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from transformers import TrainingArguments, Trainer
from datasets import Dataset
import torch
# Зареждане на токенизатор и модел
model_name = "mistralai/Mistral-7B-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
num_labels=4 # брой категории за класификация
)
# Подготовка на dataset
def tokenize_function(examples):
return tokenizer(
examples["text"],
padding="max_length",
truncation=True,
max_length=512
)
# Зареждане на данни (примерен формат)
train_data = Dataset.from_dict({
"text": ["Кога ще пристигне поръчката ми?", "Искам да върна продукт."],
"label": [0, 1]
})
tokenized_dataset = train_data.map(tokenize_function, batched=True)
# Конфигурация на training
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
warmup_steps=100,
weight_decay=0.01,
logging_dir="./logs",
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
)
# Стартиране на training
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
)
trainer.train()
Hugging Face е идеален за разработчици, които искат пълен контрол и работят с open-source AI модели. Недостатъкът е, че изисква технически умения за setup и управление на compute ресурси.
Mistral Forge: Обучаване на custom AI модел от нула (март 2026)
Mistral Forge беше анонсиран на NVIDIA GTC конференцията през март 2026 като платформа за обучаване на custom AI модели от нула с proprietary данни. Това го отличава фундаментално от fine-tuning услугите на OpenAI и Anthropic — вместо да адаптирате техен модел, вие изграждате собствен.
Mistral Forge е позициониран за enterprise организации, които имат уникални изисквания за данни и архитектура — например финансови институции с регулаторни ограничения или здравни организации с чувствителни данни. Пълната контрола върху архитектурата означава и пълна собственост върху модела.
Ценообразуването на Mistral Forge все още не е публично обявено и изисква директни преговори с Mistral AI. Платформата е предназначена за организации с достатъчен обем от proprietary данни и бюджет за enterprise AI. За по-малки проекти fine-tuning на съществуващ модел остава по-практичният избор.
Подготовка на данни за обучаване на custom AI модел
Качеството на данните определя качеството на модела — без изключение. Дори перфектно конфигуриран training job ще произведе лош модел, ако данните са некачествени.
Чек-лист за подготовка на данни:
- Минимум 100 примера (препоръчително 500+)
- Всеки пример има ясен вход и очакван изход
- Няма дубликати (проверете с hash comparison)
- Консистентен формат в целия dataset
- Системният prompt е включен в training примерите
- Данните покриват edge cases и изключения
- Няма противоречиви примери (един вход, два различни очаквани изхода)
- Данните са на езика, на който ще работи моделът
- Лични данни са анонимизирани (GDPR изискване за EU данни)
- Dataset-ът е разделен: 70% train / 15% validation / 15% test
- Примерите са прегледани от domain expert (не само от AI)
Примери за добри vs лоши training данни:
| Лош пример | Добър пример |
|---|---|
| User: "Помощ" / Assistant: "Как мога да помогна?" | User: "Поръчка #123 не е пристигнала" / Assistant: "Проверих поръчка #123 — изпратена е на 10 март с DHL, tracking: BG123. Очаква се до 15 март." |
| User: "Цена?" / Assistant: "Цената зависи от продукта." | User: "Колко струва Premium план?" / Assistant: "Premium планът струва $49/месец и включва неограничени потребители, API достъп и приоритетна поддръжка." |
Ако нямате достатъчно данни, помислете за RAG (Retrieval-Augmented Generation) като алтернатива. RAG позволява на модела да "чете" вашите документи при всяка заявка, без да изисква training.
Избор на базов модел: Кой да персонализирате?
Изборът на базов модел зависи от три фактора: задачата, бюджетът и инфраструктурата. Ето сравнение на популярните опции:
| Модел | Параметри | Training цена | Inference скорост | Най-подходящ за |
|---|---|---|---|---|
| GPT-4o | ~200B (est.) | $25/млн tokens | Бърз | Сложни задачи, висока точност |
| GPT-4o Mini | ~8B (est.) | Безплатен trial | Много бърз | Прости задачи, нисък бюджет |
| Llama 3.1 8B | 8B | $0.004/1000 tokens (Bedrock) | Бърз | Open-source, AWS среда |
| Mistral 7B | 7B | Зависи от compute | Бърз | LoRA fine-tuning, Hugging Face |
За начинаещи препоръчваме да започнете с GPT-4o Mini (безплатен trial) и да преминете към по-голям модел само ако резултатите не са достатъчно добри. В повечето случаи по-малкият модел, fine-tuned с качествени данни, превъзхожда по-големия модел без fine-tuning.
За по-задълбочен анализ на разликите между водещите модели, прочетете нашето сравнение на AI модели. Ако се интересувате от open-source алтернативи, разгледайте и open-source AI модели за пълна картина на наличните опции.
Как да оцените успеха на вашия custom AI модел?
Оценката на custom AI модел изисква систематичен подход с конкретни метрики. Субективното усещане "моделът отговаря добре" не е достатъчно за production deployment.
Основни метрики:
- Accuracy: Процент правилни отговори от всички отговори. Подходяща за балансирани dataset-и.
- Precision: От всички отговори, маркирани като "положителни", колко са наистина положителни. Важна когато false positives са скъпи.
- Recall: От всички реални положителни случаи, колко е открил моделът. Важна когато false negatives са скъпи.
- F1 Score: Хармонично средно на precision и recall. Най-балансираната метрика за повечето задачи.
Как да избегнете overfitting: Ако моделът постига 95% accuracy на training set-а, но само 60% на test set-а, имате overfitting. Решенията са: намалете n_epochs, добавете повече разнообразни примери или увеличете regularization. Мониторирайте validation loss по време на training — ако validation loss започне да расте докато training loss пада, спрете обучението.
Реални примери за fine-tuning на AI с приблизителни цени
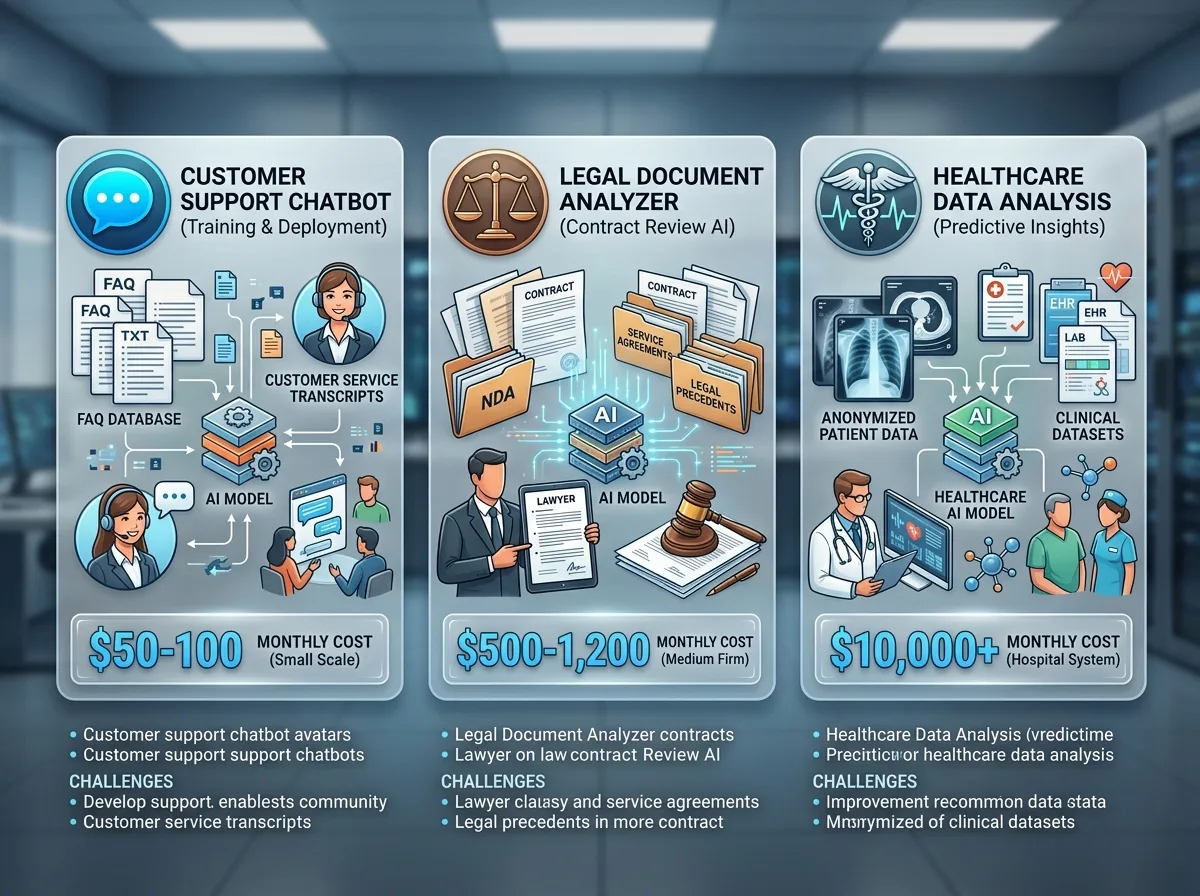
Пример 1: Customer support chatbot с ваши FAQ
Задача: Chatbot, който отговаря на въпроси за вашия продукт точно като вашия support екип.
Данни нужни: 200–500 двойки въпрос-отговор от реални клиентски разговори или FAQ документи.
Препоръчан модел: GPT-4o Mini (безплатен trial) или GPT-4o за по-сложни въпроси.
Приблизителна цена: $0–$50 за training (в рамките на free trial за малки dataset-и).
Очаквани резултати: Моделът отговаря на 80–90% от стандартните въпроси без ескалация към човек. За AI автоматизация на customer support процеси вижте нашите практически примери.
Пример 2: Юридически документ анализатор
Задача: Модел, който извлича ключови клаузи от договори и маркира рискови условия.
Данни нужни: 500–1000 анотирани договора с маркирани клаузи и категории риск.
Препоръчан модел: GPT-4o (по-висока точност за сложен юридически текст).
Приблизителна цена: $200–$500 за training + inference разходи при мащабна употреба.
Очаквани резултати: Автоматично извличане на ключови дати, страни, задължения и рискови клаузи от стандартни договори.
Пример 3: Медицински диагностичен помощник
Задача: Модел, подпомагащ лекари при анализ на симптоми и предлагане на диференциални диагнози.
Данни нужни: 2000+ анонимизирани клинични случаи с симптоми, диагнози и лечение (GDPR-compliant).
Препоръчан модел: GPT-4o или Llama 3.1 70B за максимална точност.
Приблизителна цена: $1000+ за training, плюс значителни разходи за data collection и анонимизация.
Важно: Медицинските AI приложения изискват валидация от медицински специалисти и спазване на регулаторни изисквания. Прочетете за EU AI Act и задълженията за high-risk AI системи.
Обучаване на custom AI модел в България: Контекст и възможности
Българският IT сектор предлага реална база за custom AI training. Според BASSCOM Barometer 2025, над 60 000 разработчици работят в 6 100+ софтуерни компании — много от тях вече използват AI API-та, които могат да бъдат заменени или допълнени с fine-tuned модели.
Инфраструктура: INSAIT и Sofia Tech Park изграждат AI фабрика BRAIN++ за €90 милиона — суперкомпютърът Discoverer++ ще позволи обучение на големи модели локално, без зависимост от чуждестранни cloud провайдъри. Това е особено важно за организации, които обработват чувствителни данни под GDPR.
Образование: Софийски университет и ТУ-София предлагат магистратури по AI с курсове по Machine Learning и Deep Learning. INSAIT — подкрепен от Google, Amazon и DeepMind — обучава изследователи на световно ниво и създаде COMPL-AI, първата EU рамка за тестване на AI модели за съответствие с EU AI Act.
Практически съвет за БГ компании: Започнете с fine-tuning на GPT-4o Mini или Llama 3.1 8B върху данни на български от вашия домейн. Дори 200-300 примера на български (customer support чатове, правни документи, медицински записи) могат значително да подобрят качеството на отговорите спрямо стандартните модели. За компании в регулирани сектори — банки, здравеопазване, публична администрация — локалният fine-tuning с Hugging Face + RunPod ($2-32/час) елиминира нуждата от изпращане на данни към external API.
Типични грешки при fine-tuning и как да ги избегнете
1. Скачане директно към full fine-tuning
Много начинаещи стартират с full fine-tuning, защото изглежда "по-мощно". Правилният подход е да започнете с LoRA — ако не работи там, full fine-tuning рядко ще реши проблема. Ако LoRA не работи, проблемът почти сигурно е в данните.
2. Недостатъчно или некачествено данни
Сто лоши примера са по-вредни от нула примера. Моделът ще научи грешните поведения. Проверявайте всеки пример ръчно или с помощта на domain expert преди да го включите в dataset-а.
3. Противоречиви training примери
Ако dataset-ът съдържа един и същи вход с два различни очаквани изхода, моделът не може да научи правилното поведение. Използвайте скрипт за дедупликация и проверка на консистентност преди training.
4. Пропускане на системния prompt в training данните
Ако планирате да използвате системен prompt при inference, включете го в training примерите. Моделът трябва да е виждал системния prompt по време на обучение, за да го следва правилно. Прочетете нашето ръководство за prompt инженерство за добри практики.
5. Липса на evaluation преди deployment
Никога не пускайте fine-tuned модел в production без да го тествате върху отделен test set. Добрите резултати на training set-а не гарантират добри резултати в реалния свят.
Безплатни инструменти за AI fine-tuning
Можете да стартирате обучаването на custom AI модел без никакви разходи:
- OpenAI GPT-4o Mini: Fine-tuning API с ниски цени — проверете актуалните условия за безплатни tier-ове
- Google Colab: Безплатен GPU compute за Hugging Face training (T4 GPU, 12GB VRAM)
- Hugging Face Hub: Безплатен достъп до хиляди pre-trained модели и datasets
- Hugging Face Transformers: Open-source библиотека за fine-tuning без лицензионни разходи
- GitHub: Безплатен хостинг на код и версионен контрол на training скриптове
Кога трябва да платите: Преминете към платен план когато безплатните ресурси са недостатъчни — например при dataset над 2M tokens, нужда от по-бърз GPU или production deployment с висок трафик.
Сравнение на подходите за адаптиране на AI модели
- ✓Fine-tuning с OpenAI е достъпен за начинаещи без технически умения
- ✓GPT-4o Mini free trial позволява старт без разходи
- ✓Специализираните модели са до 1000x по-бързи и по-евтини при конкретна задача
- ✓LoRA намалява значително compute разходите при open-source модели
- ✓Hugging Face предлага пълен контрол и безплатни модели
- ✓Mistral Forge дава пълна собственост върху модела за enterprise
- ×Fine-tuning изисква минимум 100-1000 висококачествени примера
- ×Подготовката на данни е времеемка и изисква domain expertise
- ×OpenAI fine-tuning обвързва модела с тяхната платформа
- ×Training от нула струва $25M-$200M - недостъпно за повечето компании
- ×Overfitting е реален риск при малки dataset-и
- ×Медицинските и юридическите приложения изискват допълнителна валидация
Кои са най-честите грешки при обучаване на custom AI модел?
-
Твърде общ use case — "Искам модел, който прави всичко" води до модел, който не прави нищо добре. Дефинирайте конкретна задача.
-
Пропускане на data cleaning — Дубликати и противоречиви примери в dataset-а директно влошават качеството на модела. Отделете поне 50% от времето за подготовка на данни.
-
Игнориране на validation set — Без отделен validation set не можете да знаете дали моделът се е подобрил или само е "запомнил" training данните.
-
Неправилен избор на базов модел — Не избирайте най-скъпия модел автоматично. GPT-4o Mini fine-tuned с качествени данни често превъзхожда GPT-4o без fine-tuning за специфична задача.
-
Deployment без мониторинг — Fine-tuned моделите могат да деградират с времето, ако реалните данни се различават от training данните. Настройте мониторинг на производителността след deployment.
Как да оптимизирате обучаването на custom AI модел?
-
Използвайте DPO (Direct Preference Optimization) — OpenAI поддържа DPO fine-tuning, при което показвате на модела предпочитани vs непредпочитани отговори. Това е по-ефективно от supervised fine-tuning за задачи, свързани с тон и стил.
-
Комбинирайте LoRA с quantization — QLoRA (Quantized LoRA) намалява memory footprint с 4x при минимална загуба на точност. Позволява fine-tuning на 70B модели на единичен A100 GPU.
-
Автоматизирайте data collection — Настройте pipeline, който автоматично събира и форматира нови training примери от production трафика. Моделът ще се подобрява с времето без ръчна намеса.
-
Използвайте ensemble подход — За критични приложения комбинирайте fine-tuned модел с RAG система. Fine-tuned моделът осигурява правилния тон и формат, RAG осигурява актуалната информация.
-
Мониторирайте training loss в реално време — Ако validation loss спре да намалява докато training loss продължава да пада, имате overfitting. Спрете training-а рано (early stopping) и запазете checkpoint-а с най-нисък validation loss.
Често задавани въпроси
Каква е разликата между fine-tuning и fine-tuning с open-weight модели?+
Колко струва обучаването на custom AI модел през 2026?+
Какво е LoRA и защо е по-евтино от пълния fine-tuning?+
Какви данни са необходими за успешно обучаване на модел?+
Кой е най-добрият инструмент за начинаещи - OpenAI, Google Vertex AI или Hugging Face?+
Как да избегна overfitting при fine-tuning?+
Следващи стъпки за създаване на собствен AI модел
Обучаването на custom AI модел е достъпно за всеки бизнес — не само за tech компании с ML екипи. Ключовото разбиране е, че 80% от успеха зависи от качеството на данните, не от избора на модел или платформа.
Конкретна следваща стъпка за днес: Отворете platform.openai.com, регистрирайте се и създайте JSONL файл с 50 примера от вашия use case. OpenAI предлага достъпни цени за fine-tuning, които позволяват старт с минимален бюджет. Ако имате нужда от помощ с форматирането на примерите, прочетете нашето ръководство за prompt инженерство — принципите за добри prompts важат и за training данни.
За по-сложни приложения с автоматизация на бизнес процеси, вижте нашите практически примери за AI автоматизация — custom модели и автоматизация работят най-добре заедно.
Допълнителни ресурси
- OpenAI Fine-tuning документация — официално ръководство с актуални примери
- Hugging Face Transformers документация — пълно ръководство за fine-tuning с код
- Google Vertex AI Training Overview — официална документация за custom training
- Amazon Bedrock Fine-tuning — ръководство за AWS потребители
- Epoch AI: Cost of Training Frontier Models — задълбочен анализ на разходите за training
- Hugging Face PEFT библиотека — за LoRA и parameter-efficient fine-tuning
Основател на CyberNinjas.ai и Кибер Хора. Пише за AI инструменти, новини и практически ръководства.
Още статии
 AI Ръководства17 мин.
AI Ръководства17 мин.ChatGPT Memory и Projects: персонален AI асистент [2026]
Изградете персонален AI асистент с ChatGPT Memory и Projects стъпка по стъпка — пълен setup за 30 минути, 5 use cases, FAQ и съвети за начинаещи [2026].
 AI Ръководства21 мин.
AI Ръководства21 мин.Claude Code + Antigravity: от нула до AI оркестратор [2026]
Claude Code + Google Antigravity IDE — пълен наръчник: настройка, CLI команди, MCP сървъри, Skills, Hooks и агентна оркестрация стъпка по стъпка [2026].
 AI Ръководства14 мин.
AI Ръководства14 мин.Claude Code + NotebookLM чрез MCP: пълен наръчник [2026]
Claude Code + NotebookLM чрез MCP — пълен наръчник за настройка стъпка по стъпка. Нулеви халюцинации, автономно проучване и citation-backed отговори [2026].